1 前言
自5.0开始,RocketMQ开始用DDD思想划分,包括Topic、Message、Queue、Producer、Consumer、ConsumerGroup、Subscription等。这些概念已经在基础知识一文中有做介绍。
本章主要学习和介绍RocketMQ的存储设计。
2 领域模型
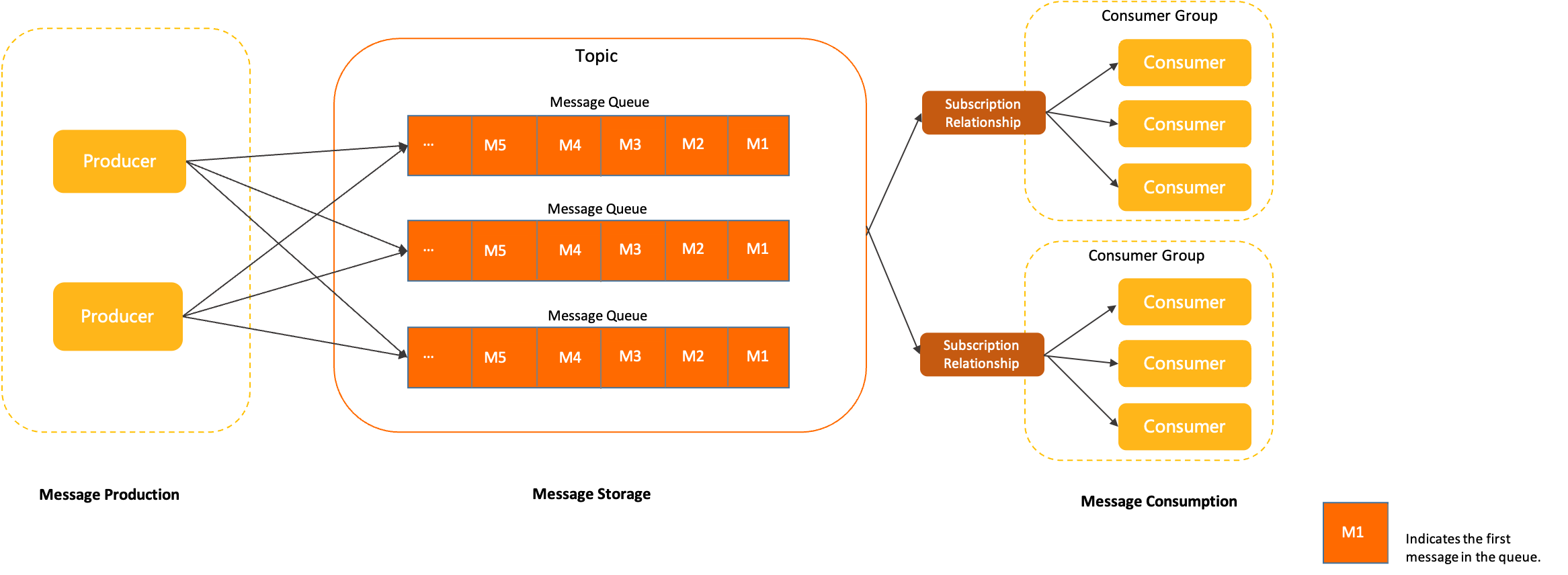
3 存储
3.1 存储文件
一般位于broker的store/之下,其包含的文件、目录如下:
[root@1ef139d74985 store]# ll /home/rocketmq/store/
total 24
-rw-r--r-- 1 rocketmq rocketmq 0 Jul 17 10:36 abort
-rw-r--r-- 1 rocketmq rocketmq 4096 Jul 17 10:52 checkpoint
drwxr-xr-x 2 rocketmq rocketmq 4096 Jul 17 10:37 commitlog
drwxr-xr-x 2 rocketmq rocketmq 4096 Jul 17 10:53 config
drwxr-xr-x 6 rocketmq rocketmq 4096 Jul 17 10:39 consumequeue
drwxr-xr-x 2 rocketmq rocketmq 4096 Jul 17 10:37 index
-rw-r--r-- 1 rocketmq rocketmq 4 Jul 17 10:36 lock其中:
commitLog:消息存储目录config:运行期间一些配置信息consumerqueue:消息消费队列存储目录index:消息索引文件存储目录abort:如果存在改文件则Broker非正常关闭checkpoint:文件检查点,存储CommitLog文件最后一次刷盘时间戳、consumerqueue最后一次刷盘时间,index索引文件最后一次刷盘时间戳。
3.2 存储结构
RocketMQ 消息的存储是由ConsumeQueue和CommitLog配合完成的,消息真正的物理存储文件是CommitLog,ConsumeQueue是消息的逻辑队列,类似数据库的索引文件,存储的是指向物理存储的地址。
每个 Topic 下的每个 Message Queue 都有一个对应的
ConsumeQueue文件。
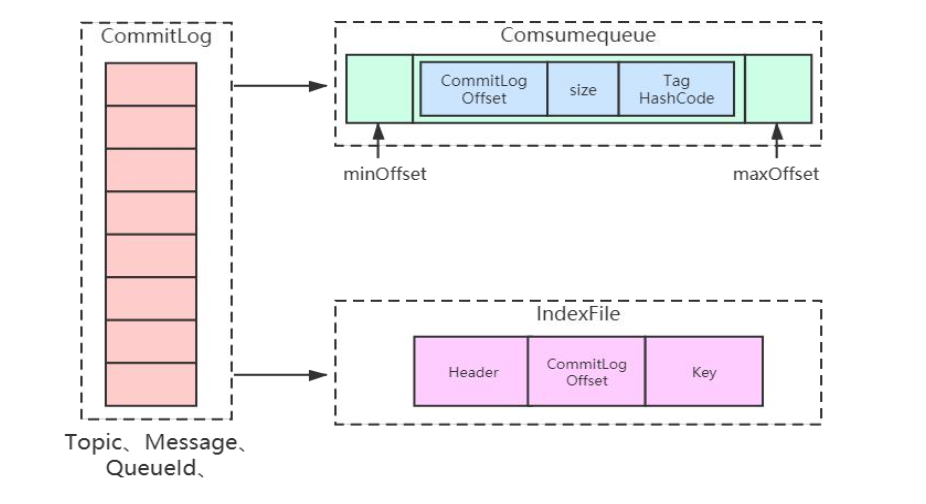
CommitLog:存储消息的元数据ConsumerQueue:存储消息在CommitLog的索引IndexFile:为了消息查询提供了一种通过key或时间区间来查询消息的方法,这种通过IndexFile来查找消息的方法不影响发送与消费消息的主流程。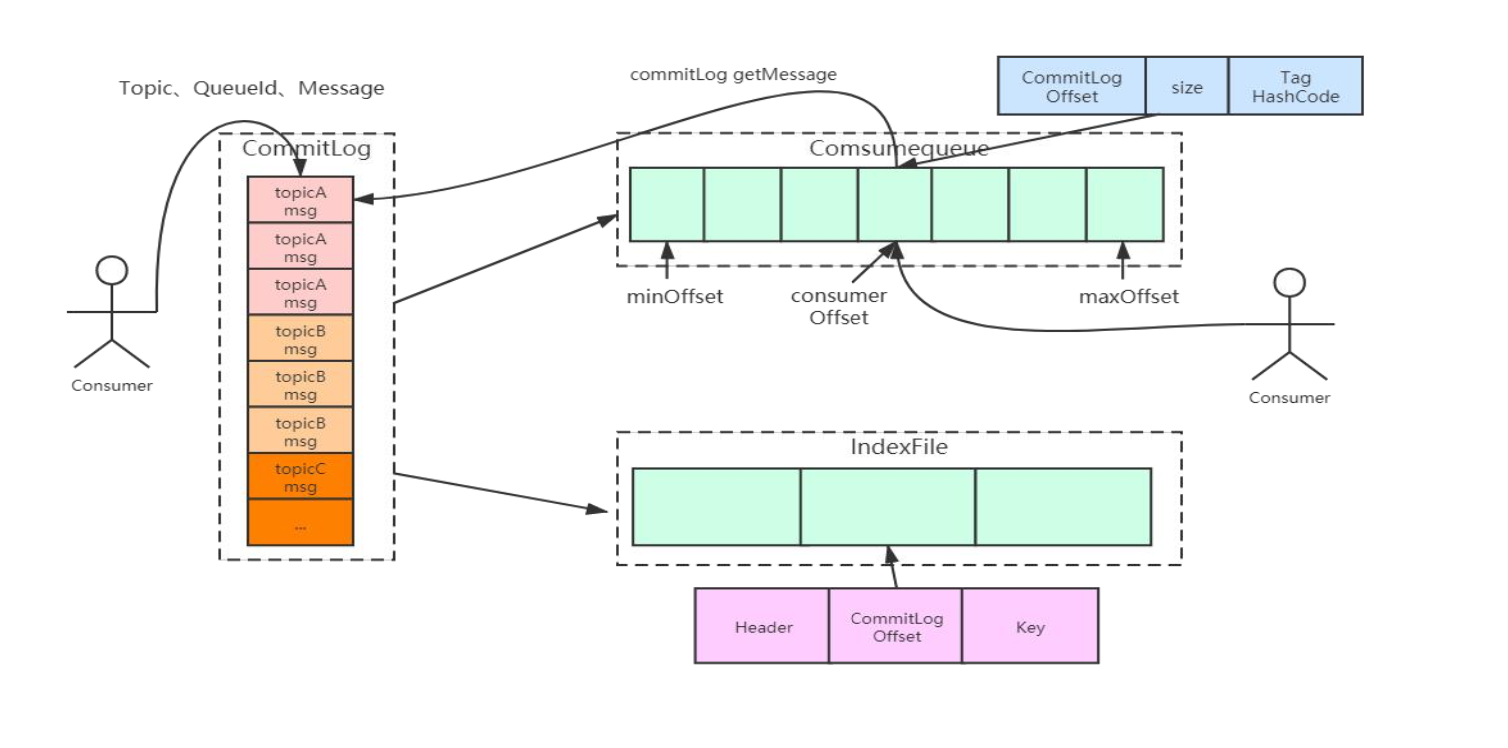 消息在文件中的关联
消息在文件中的关联
3.2.1 CommitLog
CommitLog以物理文件的方式存放,每台Broker上的CommitLog被本机器所有ConsumeQueue共享,文件地址:${user.home}\store\${commitlog}\${fileName}。
在CommitLog中,一个消息的存储长度是不固定的,RocketMQ采取一些机制,尽量向CommitLog中顺序写,但是随机读。CommitLog文件默认大小为1G,可通过在broker置文件中设置mappedFileSizeCommitLog属性来改变默认大小。
[root@1ef139d74985 store]# ll -alh commitlog/
total 12K
drwxr-xr-x 2 rocketmq rocketmq 4.0K Jul 17 10:37 .
drwxr-xr-x 6 rocketmq rocketmq 4.0K Jul 17 10:37 ..
-rw-r--r-- 1 rocketmq rocketmq 1.0G Jul 17 10:39 00000000000000000000
-rw-r--r-- 1 rocketmq rocketmq 1.0G Jul 17 10:37 00000000001073741824CommitLog文件存储的逻辑视图如下,每条消息的前面 4 个字节存储该条消息的总长度。但是一个消息的存储长度是不固定的。
每个CommitLog文件的大小为1G,一般情况下第一个CommitLog的起始偏移量为0,第二个CommitLog的起始偏移量为1073741824(1G=1073741824byte)。
为什么使用的是1G?——MMAP 使用时必须实现指定好内存映射的大小,mmap 在 Java 中一次只能映射 1.5~2G 的文件内存,其中RocketMQ 中限制了单文件1G来避免这个问题。
文件名,长度为20位,左边补零,剩余为起始偏移量
每台Rocket只会往一个CommitLog文件中写,写完一个接着写下一个。
indexFile和ComsumerQueue中都有消息对应的物理偏移量,通过物理偏移量就可以计算出该消息位于哪个CommitLog文件上。
3.2.2 ConsumeQueue
ConsumeQueue是消息的逻辑队列,类似数据库的索引文件,存储的是指向物理存储的地址。每个Topic下的每个MessageQueue都有一个对应的ConsumeQueue文件,文件地址在${$storeRoot}\consumequeue\${topicName}\${queueld}\${fileName}。
如下,Topic为TOPIC_DELAY的ConsumeQueue:
[root@1ef139d74985 store]# ll consumequeue/TOPIC_DELAY/3/00000000000000000000
-rw-r--r-- 1 rocketmq rocketmq 6000000 Jul 17 10:39 consumequeue/TOPIC_DELAY/3/00000000000000000000ConsumeQueue中存储的是消息条目,为了加速ConsumeQueue消息条目的检索速度与节省磁盘空间,每一个ConsumeQueue条目不会存储消息的全量信息,消息条目如下:
ConsumeQueue即为CommitLog文件的索引文件,其构建机制是当消息到达CommitLog文件后由专门的线程产生消息转发任务,从而构建消息消费队列文件(ConsumeQueue)与下文提到的索引文件。
存储机制这样设计有以下几个好处:
- CommitLog顺序写,可以大大提高写入效率。(实际上,磁盘有时候会比你想象的快很多,有时候也比你想象的慢很多,关键在如何使用,使用得当,磁盘的速度完全可以匹配上网络的数据传输速度。目前的高性能磁盘,顺序写速度可以达到
600MB/s,超过了一般网卡的传输速度,这是磁盘比想象的快的地方;但是磁盘随机写的速度只有大概100KB/s,和顺序写的性能相差6000倍!)- 虽然是随机读,但是利用操作系统的
page cache机制,可以批量地从磁盘读取,作为cache存到内存中,加速后续的读取速度。- 为了保证完全的顺序写,需要ConsumeQueue这个中间结构,因为ConsumeQueue里只存偏移量信息,所以尺寸是有限的,在实际情况中,大部分的ConsumeQueue能够被全部读入内存,所以这个中间结构的操作速度很快,可以认为是内存读取的速度。此外为了保证CommitLog和ConsumeQueue的一致性,CommitLog里存储了
ConsumeQueues、MessageKey、Tag等所有信息,即使ConsumeQueue丢失,也可以通过CommitLog完全恢复出来。
3.2.3 IndexFile
RocketMQ还支持通过MessageID或者MessageKey来查询消息。
使用ID查询时,因为ID就是用broker + offset生成的(这里msgId指的是服务端的),所以很容易就找到对应的CommitLog文件来读取消息。
但是对于用MessageKey来查询消息,RocketMQ则通过构建一个index来提高读取速度。
index存的是索引文件,这个文件用来加快消息查询的速度。消息消费队列RocketMQ专门为消息订阅构建的索引文件,提高根据主题与消息检索消息的速度,使用Hash索引机制,具体是Hash槽与Hash冲突的链表结构。(这里不做过多解释)
3.2.5 Config
config文件夹中存储着Topic和Consumer等相关信息。主题和消费者群组相关的信息就存在在此。
topics.json:topic配置属性subscriptionGroup.json:消息消费组配置信息。delayOffset.json:延时消息队列拉取进度。consumerOffset.json:集群消费模式消息消进度。consumerFilter.json:主题消息过滤信息。
3.2.6 其他
abort:如果存在abort文件说明Broker非正常关闭,该文件默认启动时创建,正常退出之前删除;checkpoint:文件检测点,存储CommitLog文件最后一次刷盘时间戳、ConsumeQueue最后一次刷盘时间、index索引文件最后一次刷盘时间戳。
4 过期文件删除
由于 RocketMQ 操作CommitLog,ConsumeQueue文件是基于内存映射机制,并在启动的时候会加载CommitLog,ConsumeQueue目录下的所有文件,为了避免内存与磁盘的浪费,不可能将消息永久存储在消息服务器上,所以需要引入一种机制来删除已过期的文件。
4.1 两个过程
- 清理消息存储文件(CommitLog文件)
- 清理消息消费队列文件(ConsumeQueue文件)
消息消费队列文件与消息存储文件共用一套过期文件机制。
RocketMQ 清除过期文件的方法是:如果非当前写文件在一定时间间隔内没有再次被更新,则认为是过期文件,可以被删除, RocketMQ 不会关注这个文件上的消息是否全部被消费。默认每个文件的过期时间为72 小时(不同版本的默认值不同,这里以 4.7.0 为例) ,通过在 Broker 配置文件中设置 fileReservedTime来改变过期时间,单位为小时。
org.apache.rocketmq.store.config.MessageStoreConfig中可以找到fileReservedTime的默认值。private int fileReservedTime = 72;
触发文件清除操作的是一个定时任务,而且只有定时任务,文件过期删除定时任务的周期由该删除决定,默认每 10s 执行一次。如下源码所示:
package org.apache.rocketmq.store;
public class DefaultMessageStore implements MessageStore {
private void addScheduleTask() {
this.scheduledExecutorService.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
DefaultMessageStore.this.cleanFilesPeriodically();
}
}, 1000 * 60, this.messageStoreConfig.getCleanResourceInterval(), TimeUnit.MILLISECONDS);
}
}其中this.messageStoreConfig.getCleanResourceInterval()同样位于org.apache.rocketmq.store.config.MessageStoreConfig中,其默认值源码中是这样子的:
// Resource reclaim interval
private int cleanResourceInterval = 10000;4.2 过期判断
除了上述中的fileReservedTime参数,另外还有其他两个配置参数:
deletePhysicFilesInterval:删除物理文件的时间间隔(默认是100ms),在一次定时任务触发时,可能会有多个物理文件超过过期时间可被删除,因此删除一个文件后需要间隔deletePhysicFilesInterval这个时间再删除另外一个文件,由于删除文件是一个非常耗费I/O的操作,会引起消息插入消费的延迟(相比于正常情况下),所以不建议直接删除所有过期文件。destroyMapedFileIntervalForcibly:在删除文件时,如果该文件还被线程引用,此时会阻止此次删除操作,同时将该文件标记不可用并且纪录当前时间戳,该参数表示文件在第一次删除拒绝后,文件保存的最大时间,在此时间内一直会被拒绝删除,当超过这个时间时,会将引用每次减少 1000,直到引用小于等于 0为止,即可删除该文件。
4.3 删除条件
- 指定删除文件的时间点, RocketMQ 通过
deleteWhen设置一天的固定时间执行一次。删除过期文件操作, 默认为凌晨4 点。 - 磁盘空间是否充足,如果磁盘空间不充足(
DiskSpaceCleanForciblyRatio,磁盘空间强制删除文件水位,默认是85),会触发过期文件删除操作。
5 零拷贝
指计算机执行操作时,CPU 不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省 CPU 周期和内存带宽。
5.1 作用
- 可以减少数据拷贝和共享总线操作的次数,消除传输数据在存储器之间不必要的中间拷贝次数,从而有效地提高数据传输效率;
- 减少了用户进程地址空间和内核地址空间之间因为
上下文切换而带来的开销。
没有说不需要拷贝,只是说减少冗余、或者说是减少不必要的拷贝。
使用了零拷贝技术的组件:Kafka、Netty、Rocketmq、Nginx、Apache。
5.2 原理及流程
在讲解零拷贝之前,先说说传统数据传送的机制和流程,后面就很直观地有了对比,非常容易找到零拷贝与其的改进之处,还有优势。
5.2.1 传统数据传送机制
上图。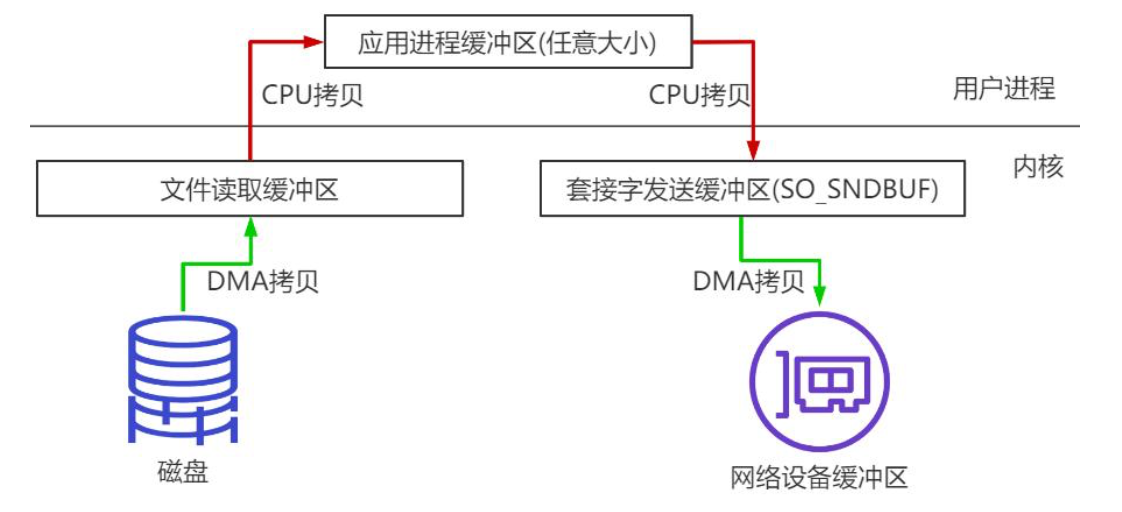
其4次拷贝流程如下:
- 第一次:将磁盘文件,读取到
操作系统内核缓冲区; - 第二次:将内核缓冲区的数据,copy 到
应用程序的buffer; - 第三步:将应用程序buffer中的数据,copy 到
socket 网络发送缓冲区(属于操作系统内核的缓冲区); - 第四次:将socket buffer 的数据,copy 到
网卡,由网卡进行网络传输。
传统的数据传送所消耗的成本:4 次拷贝,4 次上下文切换,其中,4 次拷贝中两次是DMA copy,两次是CPU copy。
Tips: DMA,Direct Memory Access,即
直接内存访问。其本质上是一块主板上独立的芯片,允许外设设备和内存存储器之间直接进行IO数据传输,其过程不需要CPU的参与。
5.2.2 mmap 内存映射 + write
上图。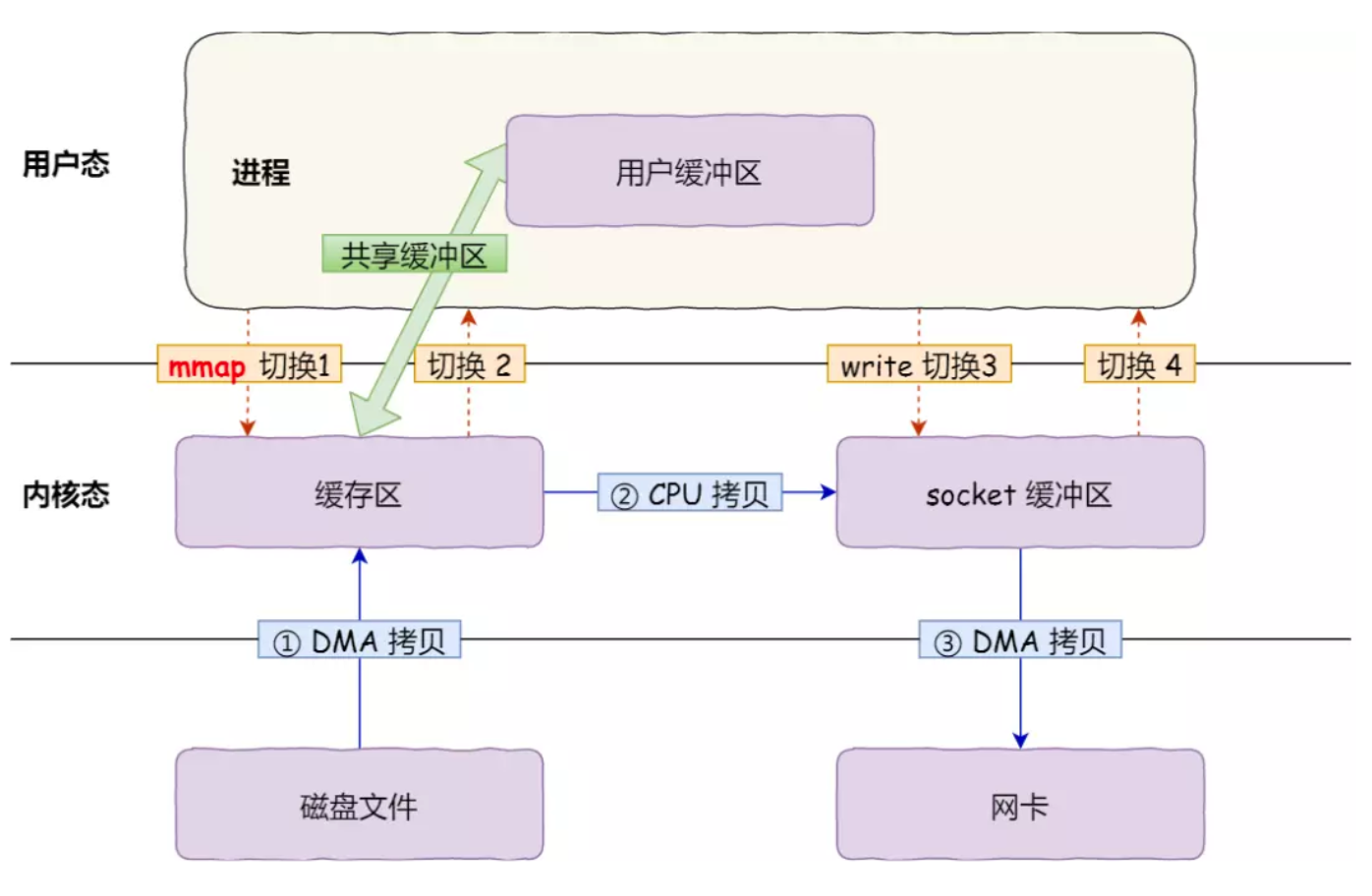
硬盘上文件的位置和应用程序缓冲区(application buffers)进行映射(一一对应关系),由于 mmap()将文件直接映射到用户空间,所以实际文件读取时根据这个映射关系,直接将文件从硬盘拷贝到用户空间,只进行了一次数据拷贝,不再有文件内容从硬盘拷贝到内核空间的一个缓冲区。
mmap 内存映射将会经历3 次拷贝: 1 次 cpu copy,2 次 DMA copy; 以及 4 次上下文切换。
5.2.2.1 RocketMQ 源码中的 MMAP 运用
RocketMQ 源码中,使用MappedFile这个类进行MMAP的映射。
public class MappedFile extends ReferenceResource {
//前后省略部分代码
public MappedFile(final String fileName, final int fileSize) throws IOException {
init(fileName, fileSize);
}
private void init(final String fileName, final int fileSize) throws IOException {
this.fileName = fileName;
this.fileSize = fileSize;
this.file = new File(fileName);
this.fileFromOffset = Long.parseLong(this.file.getName());
boolean ok = false;
ensureDirOK(this.file.getParent());
try {
// NIO
this.fileChannel = new RandomAccessFile(this.file, "rw").getChannel();
//Maps a region of this channel's file directly into memory.
this.mappedByteBuffer = this.fileChannel.map(MapMode.READ_WRITE, 0, fileSize);
TOTAL_MAPPED_VIRTUAL_MEMORY.addAndGet(fileSize);
TOTAL_MAPPED_FILES.incrementAndGet();
ok = true;
} catch (FileNotFoundException e) {
log.error("Failed to create file " + this.fileName, e);
throw e;
} catch (IOException e) {
log.error("Failed to map file " + this.fileName, e);
throw e;
} finally {
if (!ok && this.fileChannel != null) {
this.fileChannel.close();
}
}
}
}5.2.3 sendFile(Linux 2.1)
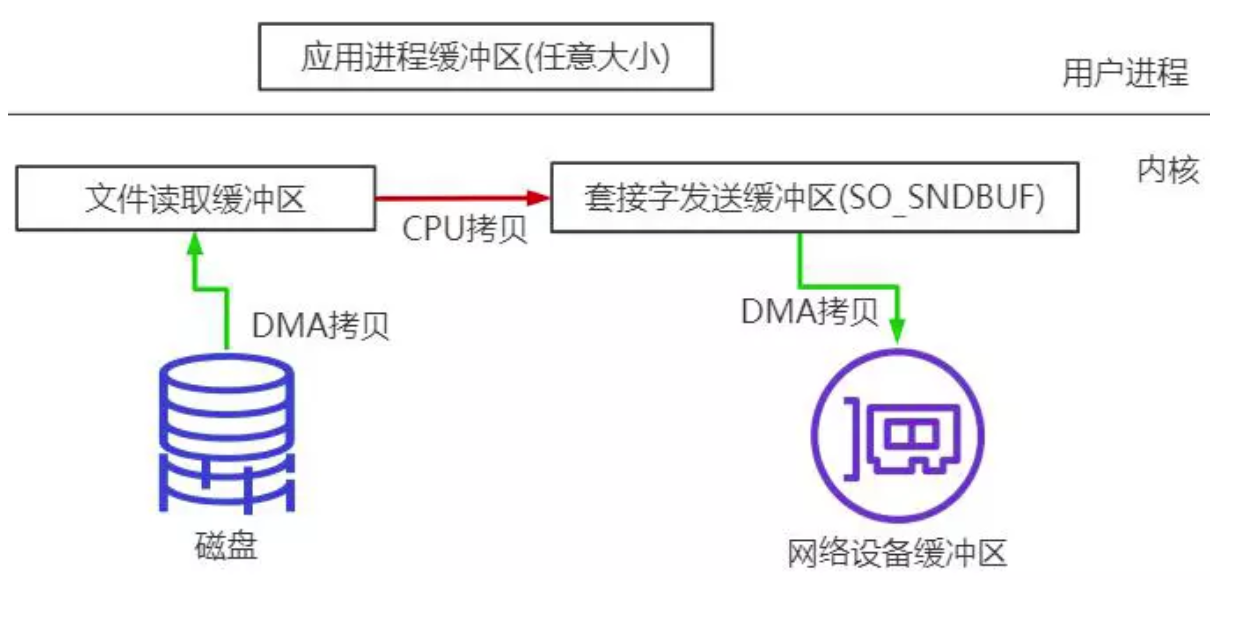
整个过程经历3 次拷贝,1 次CPU copy,2 次DMA copy。
5.2.4 sendFile + scatter/gather(Linux 2.4)
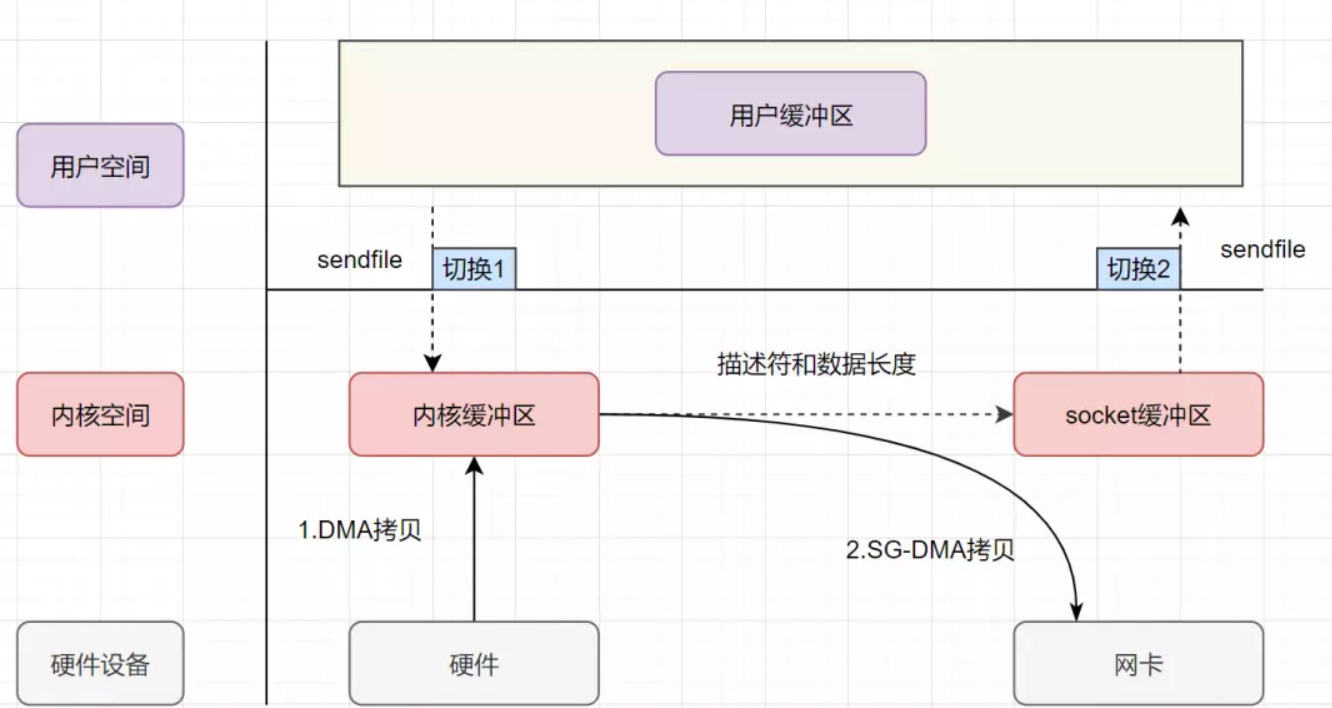
整个过程经历2次上下文切换以及2次数据拷贝。
5.2.5 splice(linux 2.6)
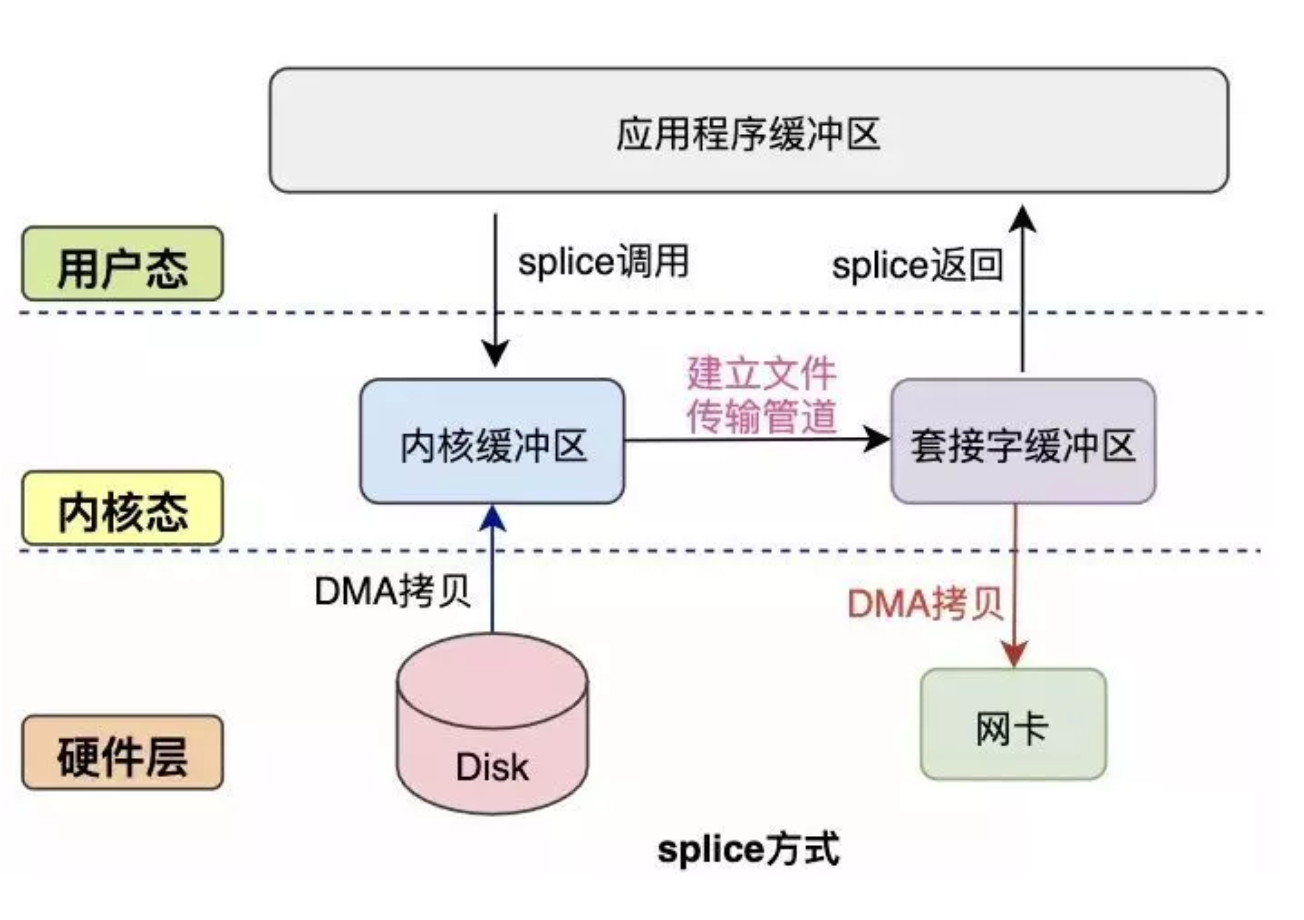
不需要硬件支持;不再限定于socket上,实现两个普通文件之间的数据零拷贝。
整个过程经历0 次cpu copy,2 次DMA copy。
局限性体现在:它的两个文件描述符参数中有一个必须是管道设备。



