1 定义
一种结构化数据的数据存储格式(类似于XML、Json)
Google出品 (开源)Protocol Buffer目前有两个版本:proto2和proto3
1.1 proto2与proto3的区别
在第一行非空白非注释行,必须写:
syntax = “proto3”;字段规则移除了
required,并把optional改名为singular;
在 proto2 中 required 也是不推荐使用的。proto3 直接从语法层面上移除了 required 规则。其实可以做的更彻底,把所有字段规则描述都撤销,原来的 repeated 改为在类型或字段名后加一对中括号。这样是不是更简洁?
repeated字段默认采用packed 编码;
在 proto2 中,需要明确使用 [packed=true] 来为字段指定比较紧凑的 packed 编码方式。
- 语言增加
Go、Ruby、JavaNano支持; - 移除了
default选项;
在 proto2 中,可以使用 default 选项为某一字段指定默认值。在 proto3 中,字段的默认值只能根据字段类型由系统决定。也就是说,默认值全部是约定好的,而不再提供指定默认值的语法。
在字段被设置为默认值的时候,该字段不会被序列化。这样可以节省空间,提高效率。但这样就无法区分某字段是根本没赋值,还是赋值了默认值。这在 proto3 中问题不大,但在 proto2 中会有问题。
比如,在更新协议的时候使用 default 选项为某个字段指定了一个与原来不同的默认值,旧代码获取到的该字段的值会与新代码不一样。
另一个重约定而弱语法的例子是go语言里的公共/私有对象。Go 语言约定,首字母大写的为公共对象,否则为私有对象。所以在 Go 语言中是没有 public、private 这样的语法的。
- 枚举类型的第一个字段必须为 0 ;
这也是一个约定。 - 移除了对分组的支持;
分组的功能完全可以用消息嵌套的方式来实现,并且更清晰。在 proto2 中已经把分组语法标注为『过期』了。这次也算清理垃圾了。
- 旧代码在解析新增字段时,会把不认识的字段丢弃,再序列化后新增的字段就没了;
在 proto2 中,旧代码虽然会忽视不认识的新增字段,但并不会将其丢弃,再序列化的时候那些字段会被原样保留。
我觉得还是 proto2 的处理方式更好一些。能尽量保持兼容性和扩展能力,或许实现起来也更简单。proto3 现在的处理方式,没有带来明显的好处,但丢掉了部分兼容性和灵活性。
- [2017-06-15 更新]:经过漫长的讨论,官方终于同意在 proto3 中恢复 proto2 的处理方式了。
- 移除了对扩展的支持,新增了
Any 类型;
Any 类型是用来替代 proto2 中的扩展的。proto2中的扩展特性很像Swift语言中的扩展。理解起来有点困难,使用起来更是会带来不少混乱。相比之下,proto3 中新增的Any类型有点像C/C++中的void*,好理解,使用起来逻辑也更清晰。
- 增加了
JSON映射特性;
语言的活力来自于与时俱进。当前,JSON的流行有其充分的理由。很多『现代化』的语言都内置了对JSON的支持,比如Go、PHP等。而C++这种看似保罗万象的学院派语言,因循守旧、故步自封,以致于现出了式微的苗头。
2 作用
通过将结构化的数据进行串行化(序列化),从而实现数据存储/RPC数据交换的功能
- 序列化:将
数据结构或对象转换成二进制串的过程; - 反序列化:将在序列化过程中所生成的
二进制串转换成数据结构或者对象的过程。
2.1 优点
- 性能方面
- 体积小:序列化后,数据大小可縮小约3倍
- 序列化遮度快:比
XML和JSON快20~100倍 - 传输速度快:因为体积小,传输起来带宽和速度会有优化
使用方面
- 使用简单:proto编译器自动进行
序列化和反序列化 - 维护成本低:多平台仅需维护一套对象协议文件 (.proto)
- 向后兼容性好:即圹展性好,不必破坏旧数据格式就可以直接对数怒结抅进行更新
- 加密性好:
Http传输内容抓包只能看到字节
- 使用简单:proto编译器自动进行
使用范围方面
- 跨平台
- 跨语吉
- 可拓展性好
2.2 缺点
- 功能方面:不适合用于对基于文本的标记文档(如 HTML)建模,因为文本不适合描述数据結构
- 其他方面
- 通用性较差:
Json、XML已经成为多种行业标准的编写工具,而protobuf只是 Google 公司内部使用的工具 - 自解释性差:以
二进制数据流方式存储(不可设),需要通过.proto文件才能了解到数据結构.
- 通用性较差:
2.3 总结
protocol Buffer比XML、Json更小、更快、使用且维护更简单。
3 应用场景
传输数据量大且网络环境不稳定的数据存储、RPC 数据交换的需求场景。如即时IM(QQ、微信)的需求场景。
4 各个语言标量类型对应关系
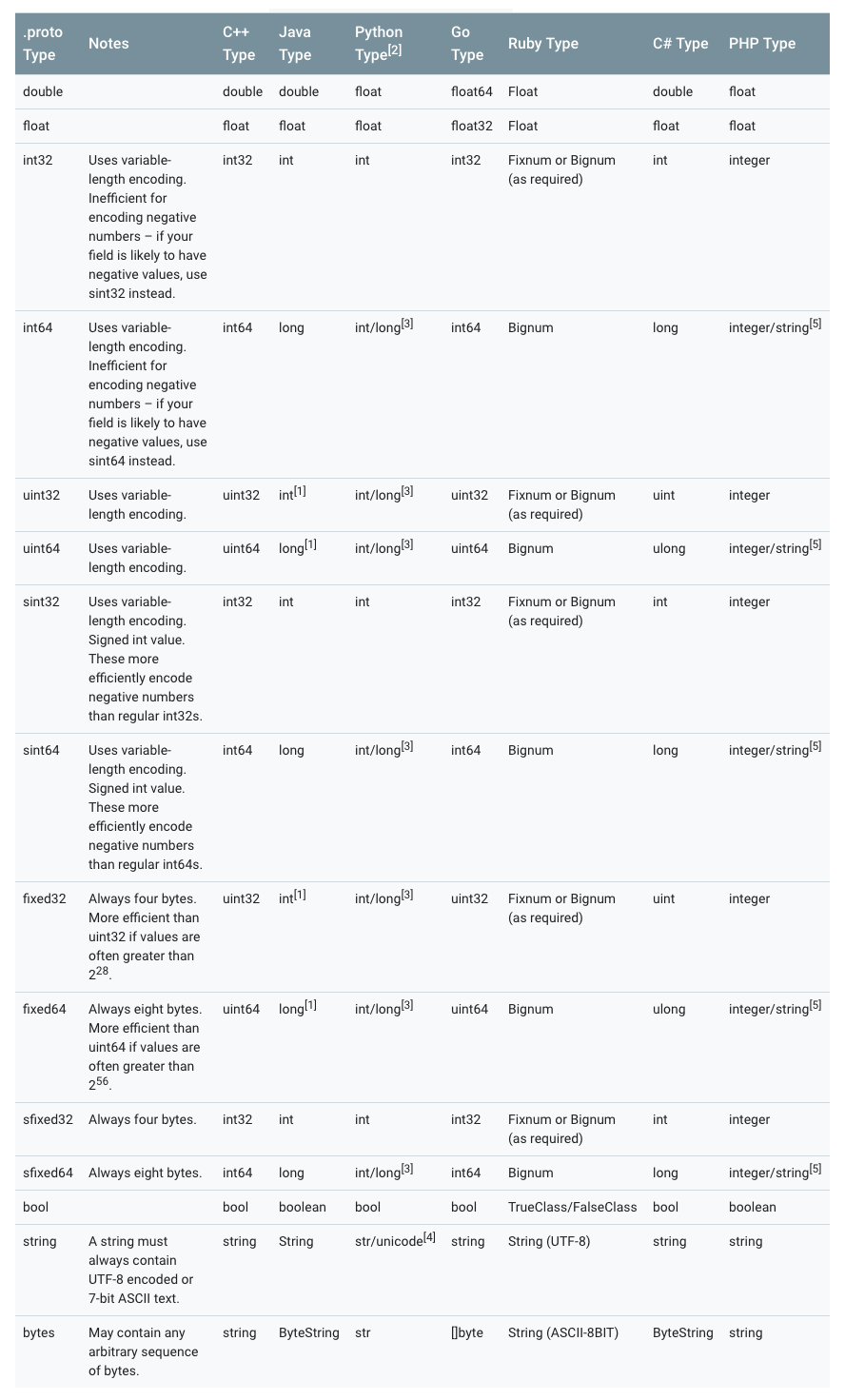
[1] 在 Java 中,无符号的 32 位和 64 位整数使用对应带符号的表示方法,最高位存储符号位。
[2] 在所有情况下,给一个字段设置一个值的时候都会执行类型检查以确保其有效。
[3] 64 位或无符号 32 位整数在解码时始终表示为 long,但是如果在设置字段的时候设置了 int,则可以为 int。 在所有情况下,该值都必须符合设置时表示的类型。参见[2]。
[4] Python 字符串在解码时表示为 unicode,但如果给出了 ASCII 字符串,则可以为 str(此字符串可能会发生变化)。
[5] 在 64 位计算机上使用 Integer,在 32 位计算机上使用 string。5 Protocol Buffer 编码原理
先给出以下三个结论:
Protocol Buffer将消息里的每个字段进行编码后,再利用T - L - V存储方式进行数据的存储,最终得到的是一个二进制字节流。其中Length可选存储,如储存Varint编码数据就不需要存储Length;Protocol Buffer对于不同数据类型采用不同的序列化方式(编码方式 & 数据存储方式),如下图: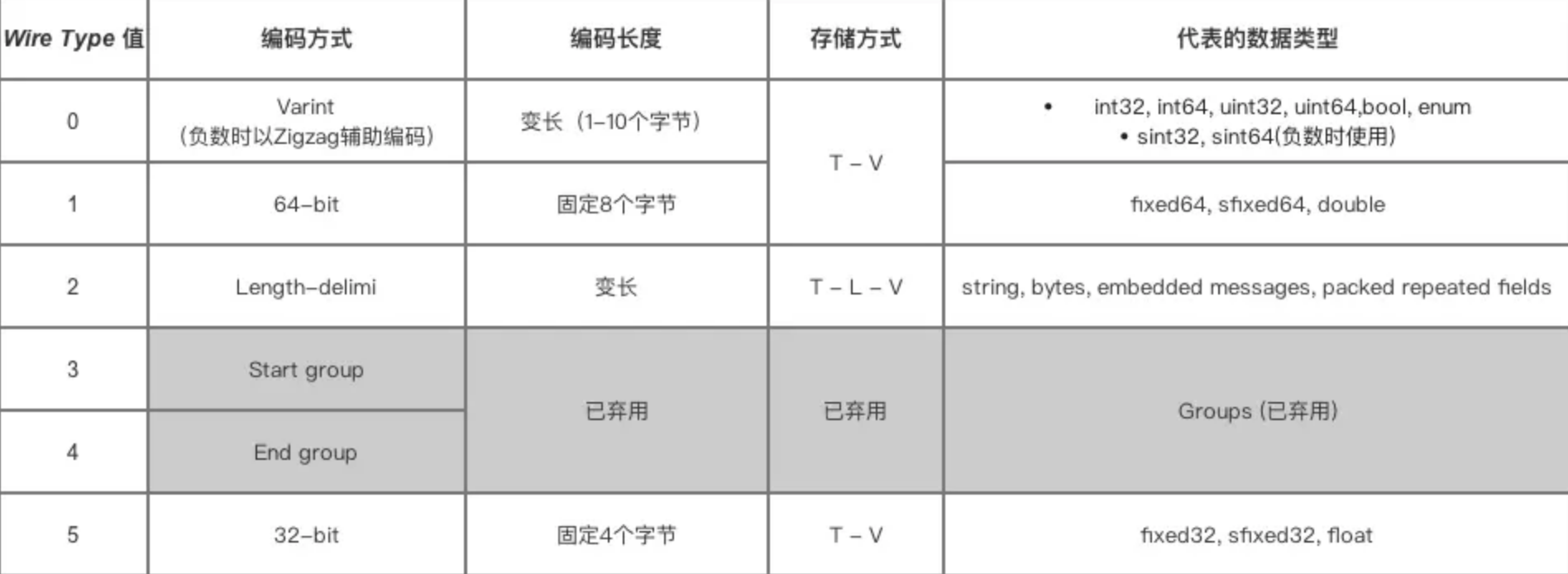 数据类型对应的编码方式
数据类型对应的编码方式注意上图中,3 和 4 已经被废弃了,所以 wire_type 取值目前只有 0、1、2、5。
- 因为
Protocol Buffer对于数据字段值的独特编码方式&T - L - V数据存储方式,使得Protocol Buffer序列化后数据量体积如此小。
5.0 T-L-V存储方式详解
即Tag - Length - Value,标识 - 长度 - 字段值存储方式。

其中:
- T:Tag,字段标识号,由
标识号(field_number)和数据类型(wire_type),即:
举例:Tag = 字段数据类型(wire_type) + 标识号(field_number)// 消息对象 message person { required int32 id = 1; // wire type = 0,field_number =1 required string name = 2; // wire type = 2,field_number =2 } // 以字段【name】为例,其Tag的二进制 = 0001 0010,由这个【0001 0010】可以推出: // 标识号( field_number) = Tag >> 3(Tag右移3位) = 0000 0010 = 2 // 数据类型(wire_type) = Tag的最低三位表示 = 010 = 2 - L:Length,Value的字节长度,可选;
对于
Varint和Zigzag编码,省略了T - L - V中的字节长度Length。 - V:Value,消息字段经过编码后的值。
- 对于
wire_type=0,那就是经过 Protocol Buffer采用Varint & Zigzag编码后的消息字段的值; - 对于
wire_type=2,如果是String类型,那就是经过UTF-8编码过后的值;如果是嵌套类型,那就是根据里面的字段数据类型进行编码后的值;
- 对于
- 具体使用:
// Tag 的具体表达式如下 Tag = (field_number << 3) | wire_type // 参数说明: // field_number:对应于 .proto文件中消息字段的标识号,表示这是消息里的第几个字段 // field_number << 3:表示 field_number = 将 Tag的二进制表示【右移三位】后的值(反推标识号怎么从Tag算出) // field_number左移3位不会导致数据丢失,因为表示范围还是足够大地去表示消息里的字段数目 // wire_type:表示 字段 的数据类型 // wire_type = Tag的二进制表示的最低三位值 // wire_type的取值 enum WireType { WIRETYPE_VARINT = 0, WIRETYPE_FIXED64 = 1, WIRETYPE_LENGTH_DELIMITED = 2, WIRETYPE_START_GROUP = 3, WIRETYPE_END_GROUP = 4, WIRETYPE_FIXED32 = 5 }; // 从上面可以看出,【wire_type】最多占用【3位】的内存空间(因为3位足以表示 0-5 的二进制)
5.1 无符号数
5.1.1 Varint编码方式介绍
- 定义:一种
变长的编码方式 - 原理:用
字节表示数字:值越小的数字,使用越少的字节数表示 - 作用:通过减少表示数字的字节数,从而进行数据压缩
- 源码:
private void writeVarint32(int n) { int idx = 0; while (true) { if ((n & ~0x7F) == 0) { i32buf[idx++] = (byte)n; break; } else { i32buf[idx++] = (byte)((n & 0x7F) | 0x80); // 步骤1:取出字节串末7位 // 对于上述取出的7位:在最高位添加1构成一个字节 // 如果是最后一次取出,则在最高位添加0构成1个字节 n >>>= 7; // 步骤2:通过将字节串整体往右移7位,继续从字节串的末尾选取7位,直到取完为止。 } } trans_.write(i32buf, 0, idx); // 步骤3: 将上述形成的每个字节 按序拼接 成一个字节串 // 即该字节串就是经过Varint编码后的字节 }
Varint中的每个字节(最后一个字节除外)都设置了最高有效位(msb),这一位表示还会有更多字节出现。每个字节的低 7 位用于以 7 位组的形式存储数字的二进制补码表示,最低有效组首位。
因此:
- 小于 128 的数字都可以用 1个字节 表示;
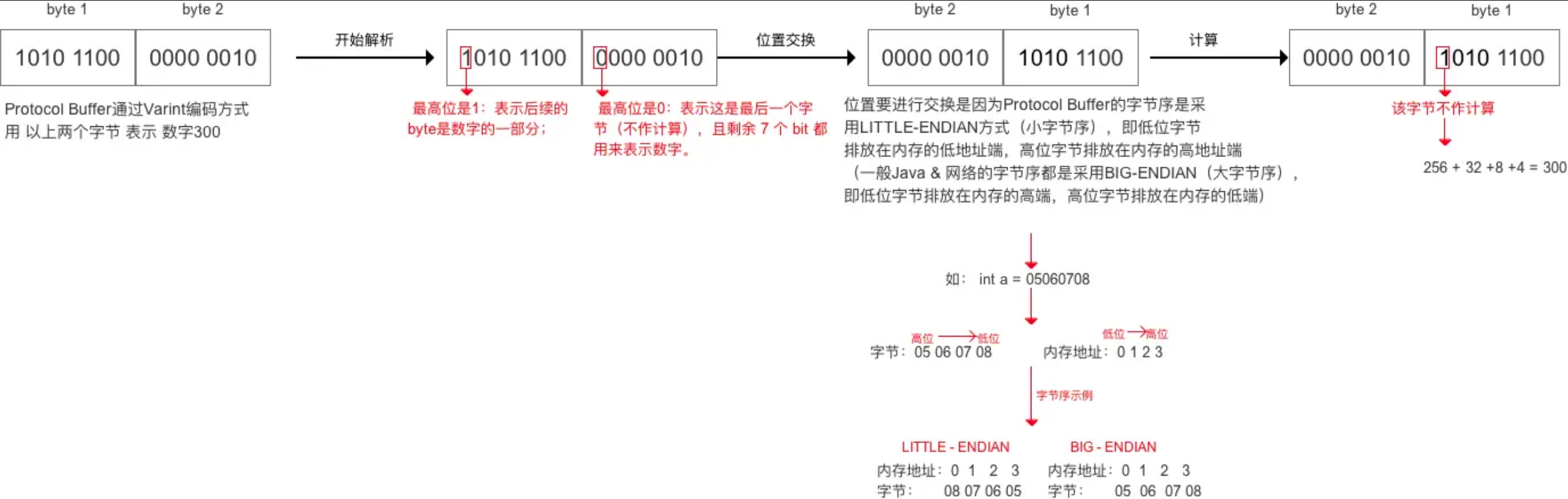
- 大于 128 的数字,比如
300,会用两个字节来表示:10101100 00000010
5.1.2 编码
以 300 举例:
if (v < (1<<14)) {
*(ptr++) = v | B;
*(ptr++) = v>>7;
}- 100101100 | 10000000 = 1 1010 1100
- 110101100 取出末尾 7 位 = 010 1100
- 100101100 >> 7 = 10 = 0000 0010
- 1010 1100 0000 0010 (最终 Varint 结果)
两个字节就搞定300的编码。
5.1.3 解码
- 如果是多个字节,先去掉每个字节的 msb(通过逻辑或运算),每个字节只留下 7 位。
- 逆序整个结果,最多是 5 个字节,排序是 1-2-3-4-5,逆序之后就是 5-4-3-2-1,字节内部的二进制位的顺序不变,变的是字节的相对位置。
5.1.4 Varint 编码方式的不足
在计算机内,负数一般会被表示为很大的整数,因为计算机定义负数的符号位为数字的最高位。
- 问题:如果采用
Varint编码方式表示一个负数,那么一定需要 5 个 byte(因为负数的最高位是1,会被当做很大的整数去处理) - 解决方案:
Protocol Buffer定义了sint32/sint64类型表示负数,通过先采用Zigzag 编码(将有符号数转换成无符号数),再采用Varint编码,从而用于减少编码后的字节数。
5.1.5 存储方式
存储方式:T - V
5.2 有符号数
5.2.1 Zigzag编码方式
- 定义:一种
变长的编码方式; - 原理:使用
无符号数来表示有符号数字; - 作用:使得绝对值小的数字都可以采用较少字节来表示;
- 源码分析
public int int_to_zigzag(int n) // 传入的参数n = 传入字段值的二进制表示(此处以负数为例) // 负数的二进制 = 符号位为1,剩余的位数为 该数绝对值的原码按位取反;然后整个二进制数+1 { return (n <<1) ^ (n >>31); // 对于sint 32 数据类型,使用Zigzag编码过程如下: // 1. 将二进制表示数 左移1位(左移 = 整个二进制左移,低位补0) // 2. 将二进制表示数 右移31位 // 对于右移: // 首位是1的二进制(有符号数),是算数右移,即右移后左边补1 // 首位是0的二进制(无符号数),是逻辑左移,即右移后左边补0 // 3. 将上述二者进行异或 // 对于sint 64 数据类型 则为: return (n << 1> ^ (n >> 63) ; } // 附:将Zigzag值解码为整型值 public int zigzag_to_int(int n) { return(n >>> 1) ^ -(n & 1); // 右移时,需要用不带符号的移动,否则如果第一位数据位是1的话,就会补1 }
以-2进行编码为例: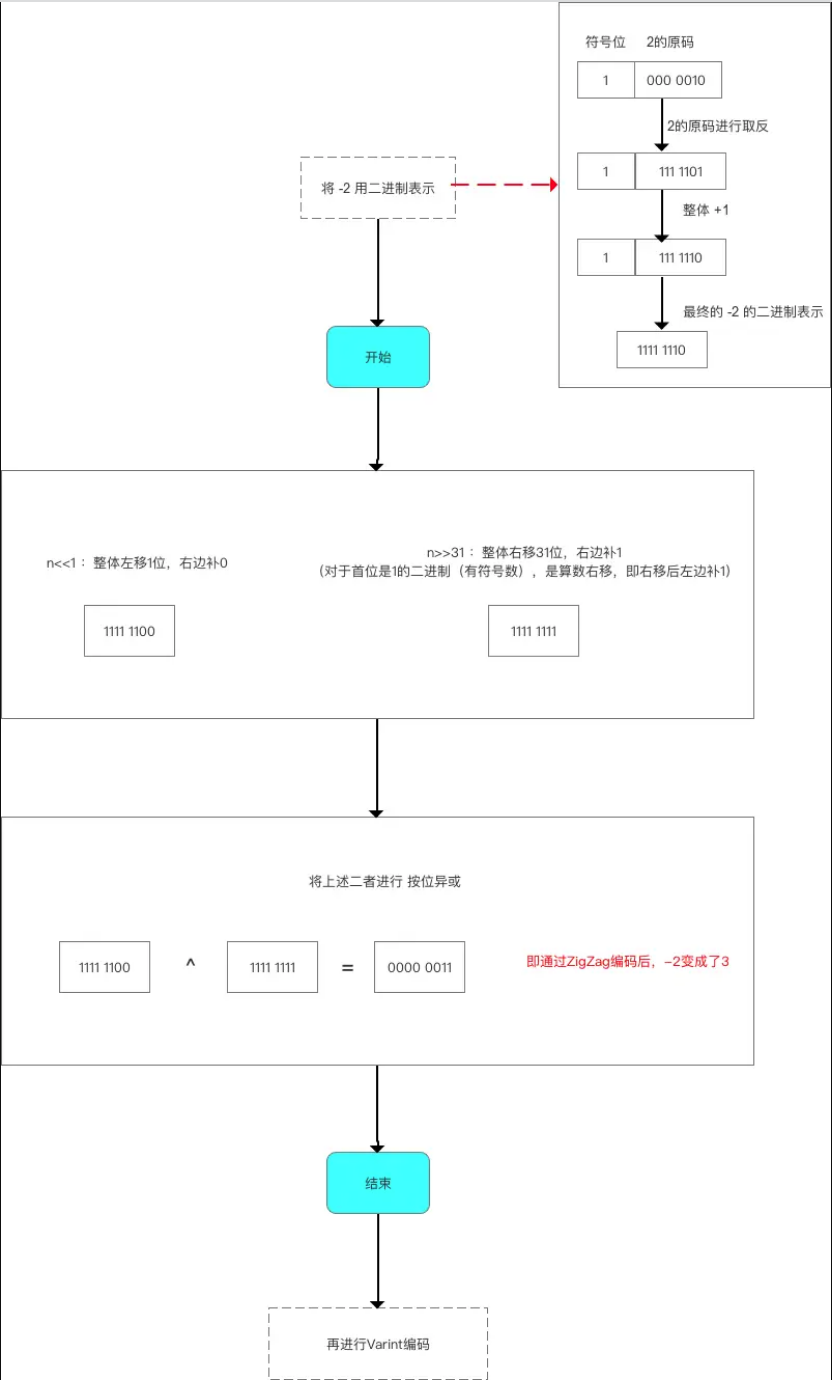
5.2.2 存储方式
存储方式:T - V
5.3 定长数
double 、fixed64 的 wire_type 为 1,在解析时告诉解析器,该类型的数据需要一个 64 位大小的数据块即可。
同理,float 和 fixed32 的 wire_type 为5,给其 32 位数据块即可。两种情况下,都是高位在后,低位在前。
64(32)-bit编码方式较简单:编码后的数据具备固定大小 = 64位(8字节)or 32位(4字节)- 采用
T - V方式进行数据存储。说
Protocol Buffer压缩数据没有到极限,原因就在这里,因为并没有压缩float、double这些浮点类型。
5.4 String类型

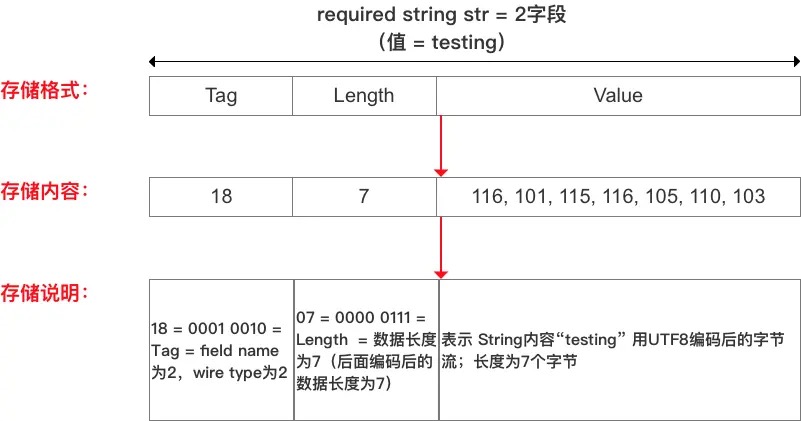
Value采用UTF-8编码,存储方式则采用T-L-V,比如:
message Test2
{
required string str = 2;
}
// 将str设置为:testing
// Test2.setStr(“testing”)
// 经过protobuf编码序列化后的数据以二进制的方式输出
// 输出为:18, 7, 116, 101, 115, 116, 105, 110, 103
5.5 嵌套消息类型
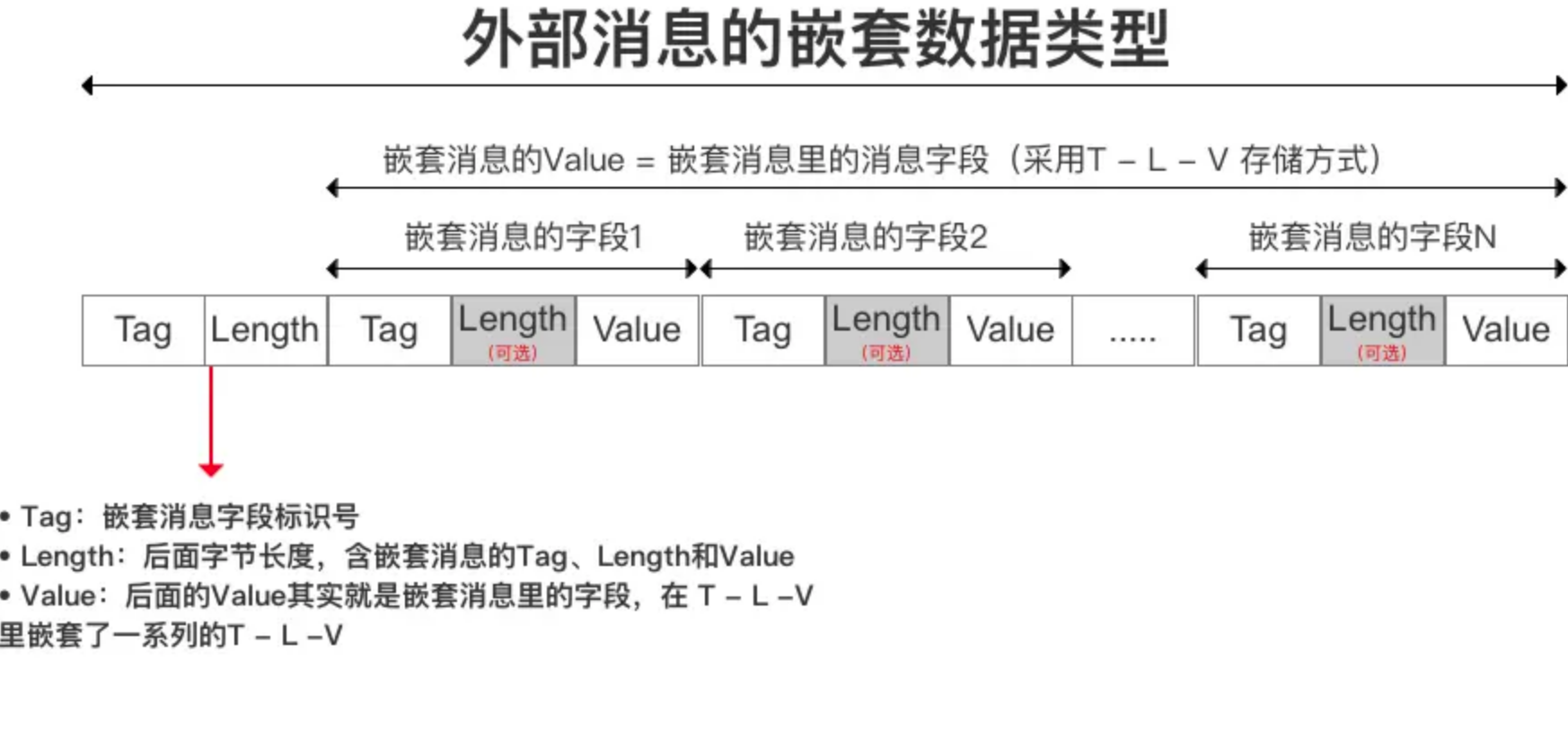
定义如下嵌套消息:
message Test2
{
// wire type = 2,field_number =2
required string str = 1;
// wire type = 0,field_number =2
required int32 id1 = 2;
}
message Test3 {
required Test2 c = 1;
}
// 将Test2中的字段str设置为:testing
// 将Test2中的字段id1设置为:296
// 编码后的字节为:10 ,12 ,18,7,116, 101, 115, 116, 105, 110, 103,16,-88,2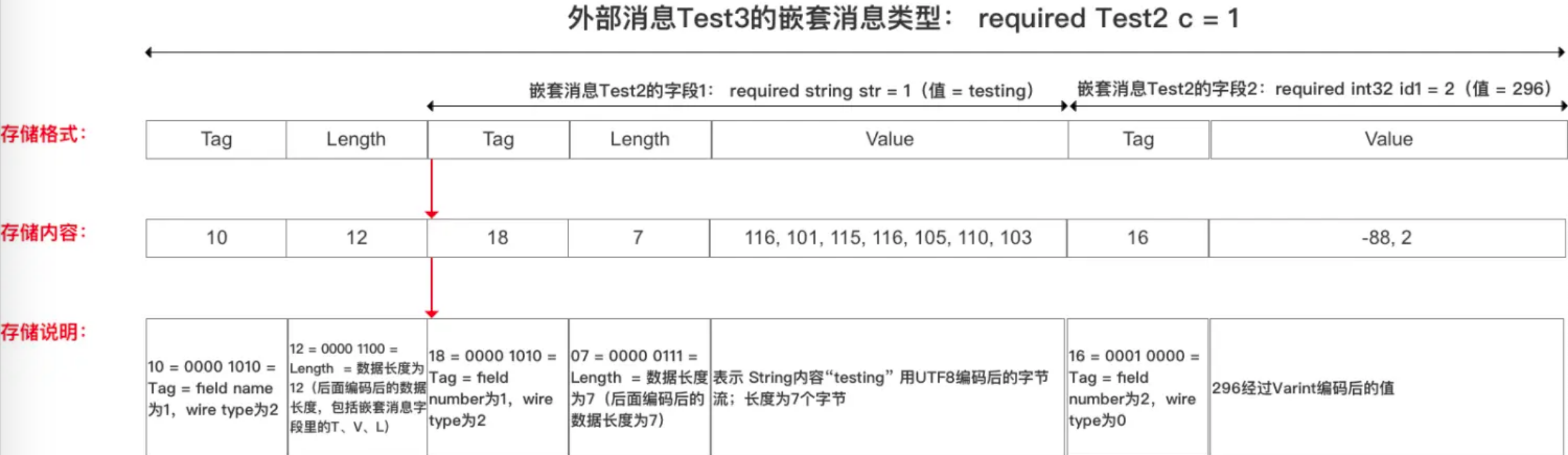
5.6 通过packed修饰的 repeat 字段
repeated类型可以看成是数组/列表
背景:对于同一个
repeated字段、多个字段值来说,他们的Tag都是相同的,即数据类型&标识号都相同;问题:若以传统的多个
T - V对存储(不带packed=true),则会导致Tag的冗余,即相同的Tag存储多次; 不带pack的存储方式
不带pack的存储方式- 解决方案:采用带packed=true 的 repeated 字段存储方式,即将相同的 Tag 只存储一次、添加
repeated字段下所有字段值的长度Length、连续存储repeated字段值,组成一个大的Tag - Length - Value -Value -Value对,即T - L - V - V - V对。

例如有如下 message 类型:
message Test4 {
repeated int32 d = 4 [packed=true];
}构造一个
Test4 字段,并且设置 repeated 字段 d 3个值:3,270和86942,编码后:22 // tag 0010 0010(field number 010 0 = 4, wire type 010 = 2)
06 // payload size (设置的length = 6 bytes)
03 // first element (varint 3)
8E 02 // second element (varint 270)
9E A7 05 // third element (varint 86942)特别注意
- required字段
必须要被设置字段值- 序列化顺序是根据
Tag标识号从小到大进行编码,和 .proto文件内字段定义的数据无关- Protocol Buffer 的
packed修饰只用于repeated字段或基本类型的repeated字段- 用在其他字段,编译
.proto文件时会报错



