1 前言
若Broker按照主从方式部署,则需要对主节点的数据进行备份。在生产上,为了实现消息的高可用,避免Broker发生单点故障引起存储在Broker上的消息无法及时消费, RocketMQ引入Broker主备机制,即:消息消费到达主服务器后需要将消息同步到消息从服务器,如果主服务器Broker宕机后,消息消费者可以从从服务器拉取消息。
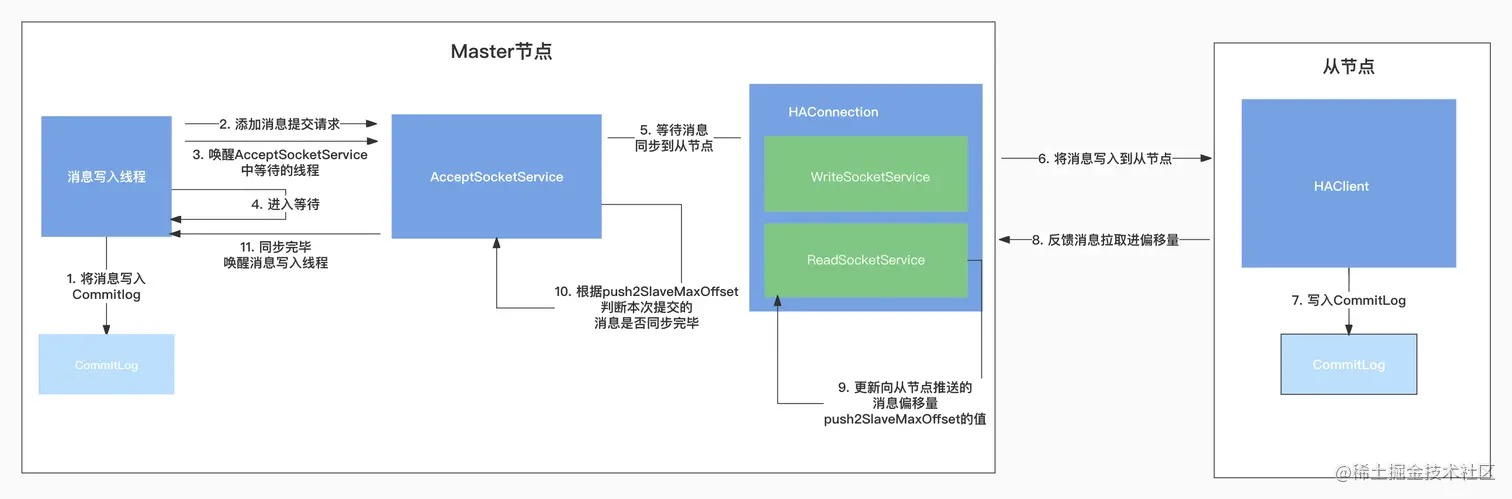
核心类:HAService:主从同步核心实现类,包括:高可用主监听从的连接、主从同步通知;HAConnection:主服务器高可用连接对象的封装,高可用主节点网络写、高可用主节点网络读;HAClient:主要是从节点上起作用,从节点发起连接请求,处理同步内容等。
整体流程:
2 同步方式
- 主从同步复制:生产者发送的每一条消息都
至少同步复制到一个slave后才返回告诉生产者成功,即“同步双写”; - 主从异步复制:生产者发送的每一条消息只要写入master 就返回告诉生产者成功,然后再“异步复制”到slave。
3 同步内容
Slave需要和Master同步的不只是消息本身,一些元数据信息也需要同步,比如TopicConfig信息、ConsumerOffset信息、DelayOffset和SubscriptionGroupConfig信息。
Broker在启动的时候,判断自己的角色是否是Slave,是的话就启动定时同步任务。
4 源码
4.1 配置
参考RocketMQ(v4.8.0)rocketmq-distribution项目的conf,该目录下有:2主2从异步HA配置(2m-2s-async)、2主2从同步HA配置(2m-2s-sync)。以下1主1从异步HA配置实例如下。
4.1.1 主节点
brokerClusterName=DefaultCluster
brokerName=broker-a
#主节点ID为0
brokerId=0
deleteWhen=04
fileReservedTime=48
#主从异步复制
brokerRole=ASYNC_MASTER
#消息异步刷盘
flushDiskType=ASYNC_FLUSH4.1.2 从节点
brokerClusterName=DefaultCluster
brokerName=broker-a
#从节点ID>0
brokerId=1
deleteWhen=04
fileReservedTime=48
#从节点
brokerRole=SLAVE
flushDiskType=ASYNC_FLUSH4.2 HAService初始化与启动
public class DefaultMessageStore implements MessageStore {
public DefaultMessageStore(final MessageStoreConfig messageStoreConfig, final BrokerStatsManager brokerStatsManager,
final MessageArrivingListener messageArrivingListener, final BrokerConfig brokerConfig) throws IOException {
// ...省略
if (!messageStoreConfig.isEnableDLegerCommitLog()) {
// 初始化HAService
this.haService = new HAService(this);
} else {
this.haService = null;
}
// ...省略
}
public void start() throws Exception {
// ...省略
if (!messageStoreConfig.isEnableDLegerCommitLog()) {
// 启动HAService
this.haService.start();
this.handleScheduleMessageService(messageStoreConfig.getBrokerRole());
}
// ...省略
}
}4.2.1 实例化
点进去HAService,可以看看实例化了哪些东西:
public HAService(final DefaultMessageStore defaultMessageStore) throws IOException {
this.defaultMessageStore = defaultMessageStore;
this.acceptSocketService = new AcceptSocketService(defaultMessageStore.getMessageStoreConfig().getHaListenPort());
this.groupTransferService = new GroupTransferService();
this.haClient = new HAClient();
}其中,
AcceptSocketService:主Broker接收从Broker的连接事件;GroupTransferService:负责主Broker向从Broker发送同步数据;HAClient:从Broker向主Broker发送连接事件;
这仨都是继承ServiceThread,即都是一个线程类,且都是 HAService的内部类。
4.2.2 启动
//HAService
public void start() throws Exception {
// 主Broker接收从Broker的连接事件,SelectionKey.OP_ACCEPT(连接事件)
this.acceptSocketService.beginAccept();
// 启动主Broker线程
this.acceptSocketService.start();
// 主Broker同步数据线程启动
this.groupTransferService.start();
// 启动从Broker发送心跳到主Broker
this.haClient.start();
}在HAService的构造函数中,创建了AcceptSocketService、GroupTransferService和HAClient,在start()方法中主要做了如下几件事:
- 调用
AcceptSocketService的beginAccept方法,这一步主要是进行端口绑定,在端口上监听从节点的连接请求(可以看做是运行在主节点的); - 调用
AcceptSocketService的start方法启动服务,这一步主要为了处理从节点的连接请求,与从节点建立连接(可以看做是运行在主节点的); - 调用
GroupTransferService的start方法,主要用于在主从同步的时候,等待数据传输完毕(可以看做是运行在主节点的); - 调用
HAClient的start方法启动,里面与主节点建立连接,向master汇报主从同步进度并存储master发送过来的同步数据(可以看做是运行在从节点的);
4.2.2.1 监听从节点连接请求
AcceptSocketService的beginAccept()方法里面首先获取了ServerSocketChannel,然后进行端口绑定,并在selector上面注册了OP_ACCEPT事件的监听,监听从节点的连接请求:
public void beginAccept() throws Exception {
// 创建ServerSocketChannel
this.serverSocketChannel = ServerSocketChannel.open();
// 获取selector
this.selector = RemotingUtil.openSelector();
// TCP可重复使用
this.serverSocketChannel.socket().setReuseAddress(true);
// 绑定端口
this.serverSocketChannel.socket().bind(this.socketAddressListen);
// 设置非阻塞
this.serverSocketChannel.configureBlocking(false);
// 注册OP_ACCEPT连接事件的监听
this.serverSocketChannel.register(this.selector, SelectionKey.OP_ACCEPT);
}4.2.2.2 处理从节点连接请求
AcceptSocketService的run()方法中,对监听到的连接请求进行了处理,处理逻辑大致如下:
- 从selector中获取到监听到的事件;
- 如果是
OP_ACCEPT连接事件,创建与从节点的连接对象HAConnection,与从节点建立连接,然后调用HAConnection的start()方法进行启动,并创建的HAConnection对象加入到连接集合中,HAConnection中封装了主节点和从节点的数据同步逻辑;
public class HAService {
class AcceptSocketService extends ServiceThread {
public void run() {
log.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
try {
this.selector.select(1000);
// 获取监听到的事件
Set<SelectionKey> selected = this.selector.selectedKeys();
if (selected != null) {
for (SelectionKey k : selected) {
// 如果是连接事件
if ((k.readyOps() & SelectionKey.OP_ACCEPT) != 0) {
SocketChannel sc = ((ServerSocketChannel) k.channel()).accept();
if (sc != null) {
HAService.log.info("HAService receive new connection, " + sc.socket().getRemoteSocketAddress());
try {
// 创建HAConnection,建立连接
HAConnection conn = new HAConnection(HAService.this, sc);
//开启连接
conn.start();
//添加连接
HAService.this.addConnection(conn);
} catch (Exception e) {
log.error("new HAConnection exception", e);
sc.close();
}
}
} else {
log.warn("Unexpected ops in select " + k.readyOps());
}
}
selected.clear();
}
} catch (Exception e) {
log.error(this.getServiceName() + " service has exception.", e);
}
}
log.info(this.getServiceName() + " service end");
}
}
}4.2.2.3 等待主从复制结束
GroupTransferService的run方法主要是为了在进行主从数据同步的时候,等待从节点数据同步完毕。
在运行时首先会调用waitForRunning进行等待,因为此时可能还没有开始主从同步,所以先进行等待,之后如果有同步请求,会唤醒该线程,然后调用doWaitTransfer方法等待数据同步完成:
public class HAService {
class GroupTransferService extends ServiceThread {
public void run() {
log.info(this.getServiceName() + " service started");
// 如果服务未停止
while (!this.isStopped()) {
try {
// 等待运行,10ms
this.waitForRunning(10);
// 如果被唤醒,调用doWaitTransfer等待主从同步完成
this.doWaitTransfer();
} catch (Exception e) {
log.warn(this.getServiceName() + " service has exception. ", e);
}
}
log.info(this.getServiceName() + " service end");
}
}
}那如何判断有数据需要同步的?
在前面章节【RocketMQ学习】9.源码之Store中,消息落地时,主Broker会调用submitReplicaRequest()方法进行消息的同步。
调用路径为:DefaultMessageStore#asyncPutMessage()、CommitLog#asyncPutMessage()、CommitLog#submitReplicaRequest().
//CommitLog
public CompletableFuture<PutMessageStatus> submitReplicaRequest(AppendMessageResult result, MessageExt messageExt) {
//判断当前Broker的角色是否是SYNC_MASTER
if (BrokerRole.SYNC_MASTER == this.defaultMessageStore.getMessageStoreConfig().getBrokerRole()) {
HAService service = this.defaultMessageStore.getHaService();
if (messageExt.isWaitStoreMsgOK()) {
if (service.isSlaveOK(result.getWroteBytes() + result.getWroteOffset())) {
//构建消息提交请求GroupCommitRequest
GroupCommitRequest request = new GroupCommitRequest(result.getWroteOffset() + result.getWroteBytes(),
this.defaultMessageStore.getMessageStoreConfig().getSyncFlushTimeout());
//添加进GroupTransferService的主从同步请求列表
service.putRequest(request);
//唤醒GroupTransferService中在等待的线程
service.getWaitNotifyObject().wakeupAll();
return request.future();
}
else {
return CompletableFuture.completedFuture(PutMessageStatus.SLAVE_NOT_AVAILABLE);
}
}
}
return CompletableFuture.completedFuture(PutMessageStatus.PUT_OK);
}所以,总结起来什么时候才会发起数据同步,有如下几个步骤,当消息被写入到CommitLog以后:
- 首先判定是否为主节点;
- 消息是否是落地了,等待同步中?
- 是否有从节点连接上了主节点?并且是否有需要同步的offset?
- 构建消息提交请求
GroupCommitRequest,调用HAService的putRequest添加到请求集合中,并唤醒GroupTransferService中在等待的线程。
接下来,才是doWaitTransfer()的事。
//HAService
private void doWaitTransfer() {
synchronized (this.requestsRead) {
//请求主从同步列表不为空
if (!this.requestsRead.isEmpty()) {
for (CommitLog.GroupCommitRequest req : this.requestsRead) {
//判断传输到从节点最大偏移量是否超过了请求中设置的偏移量
boolean transferOK = HAService.this.push2SlaveMaxOffset.get() >= req.getNextOffset();
//等待截止时间,5秒
long waitUntilWhen = HAService.this.defaultMessageStore.getSystemClock().now()
+ HAService.this.defaultMessageStore.getMessageStoreConfig().getSyncFlushTimeout();
while (!transferOK && HAService.this.defaultMessageStore.getSystemClock().now() < waitUntilWhen) {
this.notifyTransferObject.waitForRunning(1000);
//再次判断从节点同步的最大偏移量是否超过了请求中设置的偏移量
transferOK = HAService.this.push2SlaveMaxOffset.get() >= req.getNextOffset();
}
if (!transferOK) {
log.warn("transfer messsage to slave timeout, " + req.getNextOffset());
}
//唤醒在等待数据同步完毕的线程
req.wakeupCustomer(transferOK ? PutMessageStatus.PUT_OK : PutMessageStatus.FLUSH_SLAVE_TIMEOUT);
}
this.requestsRead.clear();
}
}
}在doWaitTransfer方法中,会判断CommitLog提交请求集合requestsRead是否为空,如果不为空,表示有消息写入了CommitLog,主节点需要等待将数据传输给从节点:
push2SlaveMaxOffset记录了从节点已经同步的消息偏移量,判断push2SlaveMaxOffset是否大于本次CommitLog提交的偏移量(也就是请求中设置的偏移量);- 获取请求中设置的等待截止时间;
- 开启循环,判断数据是否还未传输完毕,并且未超过截止时间,如果是则等待
1s,然后继续判断传输是否完毕,不断进行,直到超过截止时间或者数据已经传输完毕;向从节点发送的消息最大偏移量
push2SlaveMaxOffset超过了请求中设置的偏移量,表示本次同步数据传输完毕; - 唤醒在等待数据同步完毕的线程。
4.3 启动HAClient
HAClient可以看做是在从节点上运行的,主要进行的处理如下:
- 调用
connectMaster方法连接主节点,主节点上也会运行,但是它本身就是Master没有可连的主节点,所以可以忽略; - 调用
isTimeToReportOffset方法判断是否需要向主节点汇报同步偏移量,如果需要则调用reportSlaveMaxOffset方法将当前的消息同步偏移量发送给主节点; - 调用
processReadEvent处理网络请求中的可读事件,也就是处理Master发送过来的消息,将消息存入CommitLog;
public class HAService {
class HAClient extends ServiceThread {
@Override
public void run() {
log.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
try {
// 连接主节点
if (this.connectMaster()) {
// 是否需要报告消息同步偏移量
if (this.isTimeToReportOffset()) {
// 向主节点发送同步偏移量
boolean result = this.reportSlaveMaxOffset(this.currentReportedOffset);
if (!result) {
this.closeMaster();
}
}
this.selector.select(1000);
// 处理读事件,也就是主节点发送的数据
boolean ok = this.processReadEvent();
if (!ok) {
this.closeMaster();
}
// ...
} else {
this.waitForRunning(1000 * 5);
}
} catch (Exception e) {
log.warn(this.getServiceName() + " service has exception. ", e);
this.waitForRunning(1000 * 5);
}
}
log.info(this.getServiceName() + " service end");
}
}
}4.3.1 连接主节点
connectMaster方法中会获取主节点的地址,并转换为SocketAddress对象,然后向主节点请求建立连接,并在selector注册OP_READ可读事件监听.
public class HAService {
class HAClient extends ServiceThread {
// 当前的主从复制进度
private long currentReportedOffset = 0;
//连接主节点
private boolean connectMaster() throws ClosedChannelException {
if (null == socketChannel) {
String addr = this.masterAddress.get();
if (addr != null) {
// 将地址转为SocketAddress
SocketAddress socketAddress = RemotingUtil.string2SocketAddress(addr);
if (socketAddress != null) {
// 连接master
this.socketChannel = RemotingUtil.connect(socketAddress);
if (this.socketChannel != null) {
// 注册OP_READ可读事件监听
this.socketChannel.register(this.selector, SelectionKey.OP_READ);
}
}
}
// 获取CommitLog中当前最大的偏移量
this.currentReportedOffset = HAService.this.defaultMessageStore.getMaxPhyOffset();
// 更新上次写入时间
this.lastWriteTimestamp = System.currentTimeMillis();
}
return this.socketChannel != null;
}
}
}4.3.2 发送主从同步消息拉取偏移量
在isTimeToReportOffset方法中,首先获取当前时间与上一次进行主从同步的时间间隔interval,如果时间间隔interval大于配置的发送心跳时间间隔,表示需要向主节点发送从节点消息同步的偏移量,接下来会调用reportSlaveMaxOffset方法发送同步偏移量,也就是说从节点会定时向主节点发送请求,反馈CommitLog中同步消息的偏移量:
public class HAService {
class HAClient extends ServiceThread {
// 当前从节点已经同步消息的偏移量大小
private long currentReportedOffset = 0;
//是否可以上报offset
private boolean isTimeToReportOffset() {
// 获取距离上一次主从同步的间隔时间
long interval = HAService.this.defaultMessageStore.getSystemClock().now() - this.lastWriteTimestamp;
// 判断是否超过了配置的发送心跳包时间间隔
boolean needHeart = interval > HAService.this.defaultMessageStore.getMessageStoreConfig().getHaSendHeartbeatInterval();
return needHeart;
}
// 发送同步偏移量,传入的参数是当前的主从复制偏移量currentReportedOffset
private boolean reportSlaveMaxOffset(final long maxOffset) {
this.reportOffset.position(0);
// 设置数据传输大小为8个字节
this.reportOffset.limit(8);
// 设置同步偏移量
this.reportOffset.putLong(maxOffset);
this.reportOffset.position(0);
this.reportOffset.limit(8);
for (int i = 0; i < 3 && this.reportOffset.hasRemaining(); i++) {
try {
// 向主节点发送拉取偏移量
this.socketChannel.write(this.reportOffset);
} catch (IOException e) {
log.error(this.getServiceName() + "reportSlaveMaxOffset this.socketChannel.write exception", e);
return false;
}
}
// 更新发送时间
lastWriteTimestamp = HAService.this.defaultMessageStore.getSystemClock().now();
return !this.reportOffset.hasRemaining();
}
}
}4.3.3 处理网络可读事件
processReadEvent方法中处理了可读事件,也就是处理主节点发送的同步数据。
首先从socketChannel中读取数据到byteBufferRead中,byteBufferRead是读缓冲区,读取数据的方法会返回读取到的字节数,对字节数大小进行判断:
- 如果
可读字节数大于0,表示有数据需要处理,调用dispatchReadRequest方法进行处理; - 如果
可读字节数为0,表示没有可读数据,此时记录读取到空数据的次数,如果连续读到空数据的次数大于3次,将终止本次处理。
class HAClient extends ServiceThread {
// 读缓冲区,会将从socketChannel读入缓冲区
private ByteBuffer byteBufferRead = ByteBuffer.allocate(READ_MAX_BUFFER_SIZE);
private boolean processReadEvent() {
int readSizeZeroTimes = 0;
while (this.byteBufferRead.hasRemaining()) {
try {
// 从socketChannel中读取数据到byteBufferRead中,返回读取到的字节数
int readSize = this.socketChannel.read(this.byteBufferRead);
if (readSize > 0) {
// 重置readSizeZeroTimes
readSizeZeroTimes = 0;
// 处理数据,写入CommitLog
boolean result = this.dispatchReadRequest();
if (!result) {
log.error("HAClient, dispatchReadRequest error");
return false;
}
} else if (readSize == 0) {
// 记录读取到空数据的次数
if (++readSizeZeroTimes >= 3) {
break;
}
} else {
log.info("HAClient, processReadEvent read socket < 0");
return false;
}
} catch (IOException e) {
log.info("HAClient, processReadEvent read socket exception", e);
return false;
}
}
return true;
}
}4.4 HAConnection
HAConnection中封装了主节点与从节点的网络通信处理,分别在ReadSocketService和WriteSocketService中。
4.4.1 ReadSocketService
ReadSocketService启动后处理监听到的可读事件,前面知道HAClient中从节点会定时向主节点汇报从节点的消息同步偏移量,主节点对汇报请求的处理就在这里,如果从网络中监听到了可读事件,会调用processReadEvent处理读事件:
public class HAConnection {
class ReadSocketService extends ServiceThread {
@Override
public void run() {
HAConnection.log.info(this.getServiceName() + " service started");
while (!this.isStopped()) {
try {
this.selector.select(1000);
// 处理可读事件
boolean ok = this.processReadEvent();
if (!ok) {
HAConnection.log.error("processReadEvent error");
break;
}
// ...
} catch (Exception e) {
HAConnection.log.error(this.getServiceName() + " service has exception.", e);
break;
}
}
// ...
HAConnection.log.info(this.getServiceName() + " service end");
}
}
}处理可读事件:processReadEvent中从网络中处理读事件的方式与上面HAClient的dispatchReadRequest类似,都是将网络中的数据读取到读缓冲区中,并用一个变量记录已读取数据的位置,processReadEvent方法的处理逻辑如下:
- 从
socketChannel读取数据到读缓冲区byteBufferRead中,返回读取到的字节数; - 如果读取到的字节数
大于0,进入下一步;如果读取到的字节数为0,记录连续读取到空字节数的次数是否超过三次,如果超过终止处理; - 判断剩余可读取的字节数是否
大于等于8,前面知道,从节点发送同步消息拉取偏移量的时候设置的字节大小为8,所以字节数大于等于8的时候表示需要读取从节点发送的偏移量; - 计算数据在缓冲区中的位置,从缓冲区读取从节点发送的同步偏移量
readOffset; - 更新
processPosition的值,processPosition表示读缓冲区中已经处理数据的位置; - 更新
slaveAckOffset为从节点发送的同步偏移量readOffset的值; - 如果当前主节点记录的从节点的同步偏移量
slaveRequestOffset小于0,表示还未进行同步,此时将slaveRequestOffset更新为从节点发送的同步偏移量; - 如果从节点发送的同步偏移量比当前主节点的
最大物理偏移量还要大,终止本次处理(v5.0); - 调用
notifyTransferSome,更新主节点记录的向从节点同步消息的偏移量;
//ReadSocketService
private boolean processReadEvent() {
int readSizeZeroTimes = 0;
/*
byteBufferRead没有剩余空间时,则:position == limit == capacity
调用flip()方法后,则:position == 0, limit == capacity,加上processPosition = 0,说明从头开始处理
*/
if (!this.byteBufferRead.hasRemaining()) {
this.byteBufferRead.flip();
this.processPosition = 0;
}
// ByteBuffer有剩余空间,循环至byteBufferRead没有剩余空间
while (this.byteBufferRead.hasRemaining()) {
try {
// 从SocketChannel读数据到缓存中
int readSize = this.socketChannel.read(this.byteBufferRead);
if (readSize > 0) {
// 重置readSizeZeroTimes
readSizeZeroTimes = 0;
this.lastReadTimestamp = HAConnection.this.haService.getDefaultMessageStore().getSystemClock().now();
// 读取内容长度 >= 8,说明收到从Broker的拉取请求(内容是offset)
if ((this.byteBufferRead.position() - this.processPosition) >= 8) {
// 获取偏移量内容的结束位置
int pos = this.byteBufferRead.position() - (this.byteBufferRead.position() % 8);
// 从结束位置向前读取8个字节得到从点发送的同步偏移量
long readOffset = this.byteBufferRead.getLong(pos - 8);
// 更新处理位置
this.processPosition = pos;
// 从Broker反馈已完成的偏移量,更新slaveAckOffset为从节点发送的同步进度
HAConnection.this.slaveAckOffset = readOffset;
// 如果记录的从节点的同步进度小于0,表示还未进行同步
if (HAConnection.this.slaveRequestOffset < 0) {
// 更新从Broker请求拉取的偏移量
HAConnection.this.slaveRequestOffset = readOffset;
log.info("slave[" + HAConnection.this.clientAddr + "] request offset " + readOffset);
}
// 通知等待同步HA复制结果的发送消息线程
HAConnection.this.haService.notifyTransferSome(HAConnection.this.slaveAckOffset);
}
} else if (readSize == 0) {
// 判断连续读取到空数据的次数是否超过三次
if (++readSizeZeroTimes >= 3) {
break;
}
} else {
log.error("read socket[" + HAConnection.this.clientAddr + "] < 0");
return false;
}
} catch (IOException e) {
log.error("processReadEvent exception", e);
return false;
}
}
return true;
}对于
HAConnection.this.haService.notifyTransferSome(HAConnection.this.slaveAckOffset);前面在GroupTransferService中可以看到是通过push2SlaveMaxOffset的值判断本次同步是否完成的,在notifyTransferSome方法中可以看到当主节点收到从节点反馈的消息拉取偏移量时,对push2SlaveMaxOffset的值进行了更新:
public class HAService {
// 向从节点推送的消息最大偏移量
private final GroupTransferService groupTransferService;
public void notifyTransferSome(final long offset) {
// 如果传入的偏移大于push2SlaveMaxOffset记录的值,进行更新
for (long value = this.push2SlaveMaxOffset.get(); offset > value; ) {
// 更新向从节点推送的消息最大偏移量
boolean ok = this.push2SlaveMaxOffset.compareAndSet(value, offset);
if (ok) {
this.groupTransferService.notifyTransferSome();
break;
} else {
value = this.push2SlaveMaxOffset.get();
}
}
}
}4.4.2 WriteSocketService
WriteSocketService用于主节点向从节点发送同步消息,代码很长,这里列举处理逻辑,如下:
- 根据从节点发送的主从同步消息拉取偏移量
slaveRequestOffset进行判断:- 如果
slaveRequestOffset值为-1,表示还未收到从节点报告的同步偏移量,此时睡眠一段时间等待从节点发送消息拉取偏移量; - 如果
slaveRequestOffset值不为-1,表示已经开始进行主从同步进行下一步;
- 如果
- 判断
nextTransferFromWhere值是否为-1,nextTransferFromWhere记录了下次需要传输的消息在CommitLog中的偏移量,如果值为-1表示初次进行数据同步,此时有两种情况:- 如果从节点发送的拉取偏移量
slaveRequestOffset为0,就从当前CommitLog文件最大偏移量开始同步; - 如果
slaveRequestOffset不为0,则从slaveRequestOffset位置处进行数据同步;
- 如果从节点发送的拉取偏移量
- 判断上次写事件是否已经将数据都写入到从节点:
- 如果已经写入完毕,判断
距离上次写入数据的时间间隔是否超过了设置的心跳时间,如果超过,为了避免连接空闲被关闭,需要发送一个心跳包,此时构建心跳包的请求数据,调用transferData方法传输数据; - 如果上次的数据还未传输完毕,调用
transferData方法继续传输;如果还是未完成,则结束此处处理;
- 如果已经写入完毕,判断
- 根据
nextTransferFromWhere从CommitLog中获取消息,如果未获取到消息,等待100ms,如果获取到消息,从CommitLog中获取消息进行传输:- 如果获取到消息的字节数大于
最大传输的大小,设置最最大传输数量,分批进行传输; - 更新下次传输的偏移量地址,也就是
nextTransferFromWhere的值; - 根据
nextTransferFromWhere偏移量,从CommitLog中获取的消息内容,将读取到的消息数据设置到selectMappedBufferResult中; - 设置消息头信息,包括
消息头字节数、拉取消息的偏移量等; - 调用
transferData发送数据;
- 如果获取到消息的字节数大于
发送数据:transferData方法的处理逻辑如下:
- 发送消息头数据;
- 消息头数据发送完毕之后,发送消息内容,前面知道从CommitLog中读取的消息内容放入到了
selectMappedBufferResult,将selectMappedBufferResult的内容发送给从节点。
5 总结
5.1 主从同步流程
5.2 新消息写入时的同步流程