1 前言
Redis提供了丰富的数据类型,常见的有五种:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合)。
随着Redis版本的更新,后面又支持了四种数据类型:BitMap(2.2版新增)、HyperLogLog(2.8版新增)、GEO(3.2版新增)、Stream(5.0版新增)。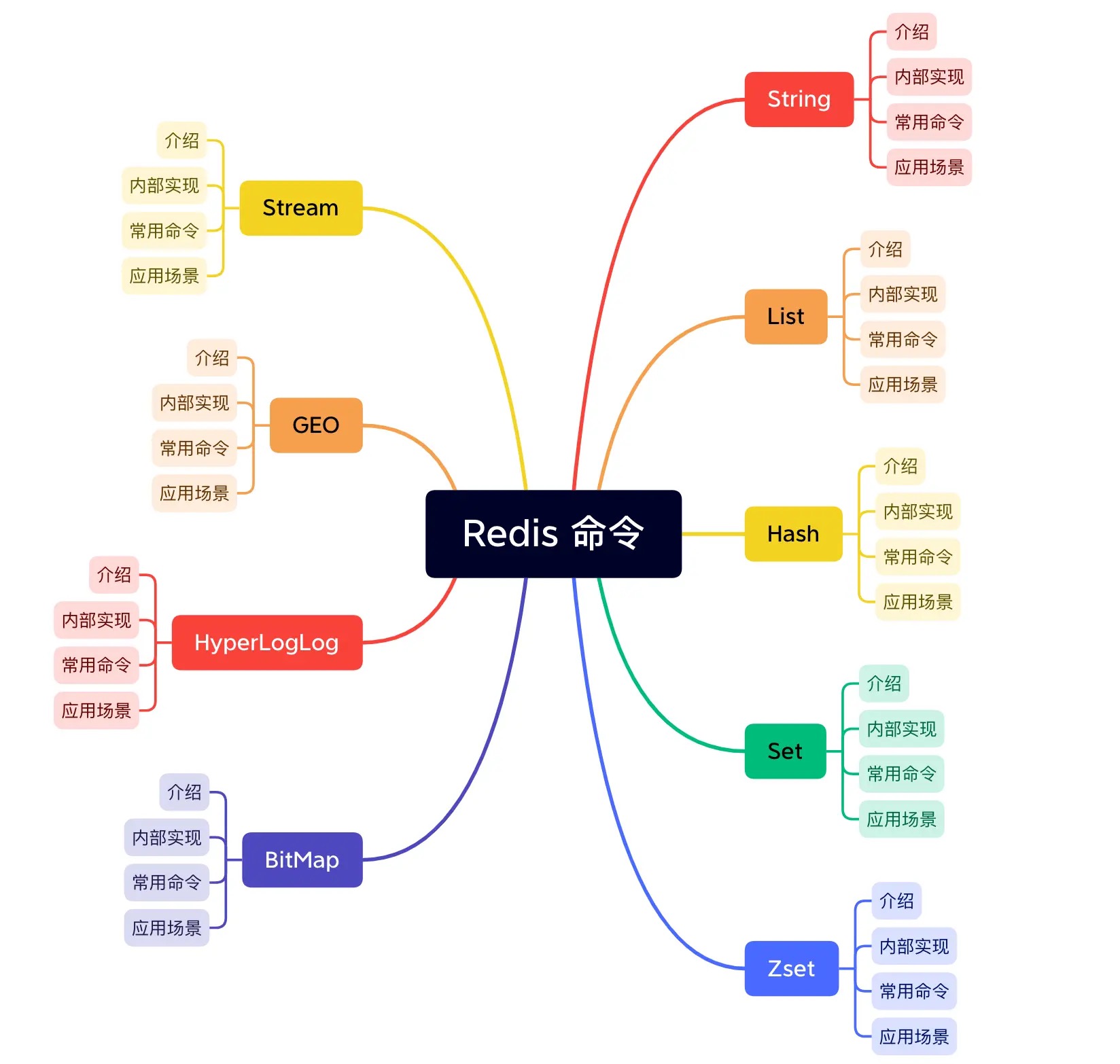
2 数据结构
Redis中所有的值对象内部定义都是redisObject结构体。结构如下图:
源码结构体:
//server.h
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount;
void *ptr;
} robj;各字段说明如下表:
| 字段名 | 说明 |
|---|---|
| type | 存储对象的类型,Redis中有5中数据类型:String,List,Hash,Set,Zset,可以通过 type {key}命令查看对象的类型,返回的是值对象类型,所有的key对象都是String类型 |
| encoding | 数据存储的Redis中后采用的是那种内部编码格式,这个后边会细讲一下 |
| lru | 记录的是对象被最后一次访问的时间,当配置了maxmemory之后,配合LRU算法对相关的key值进行删除,可以通过object idletime {key}查看key最近一次被访问的时间。也可以通过scan + object idletime命令批量查询那些键长时间没有被使用,从而可以删除长时间没有被使用的键值,减少内存的占用。 |
| refcount | 记录当前对象被引用的次数。根据当前字段来判断该对象时候可回收,当refcount为0时,可安全进行对象的回收,可以使用object refcount {key}查看当前对象引用。 |
| *ptr | 与对象的数据内容有关。如果是整数,则直接存储数据(这个地方可以了解下共享对象池,当对象为整数且范围在【0-9999】,会直接存储到共享对象池中),其他类型的数据次字段则代表的是指针。 |
2.1 String
2.1.1 介绍
String是redis中最基本的数据类型,一个key对应一个value。value可以是String、List、Set、Sorted Set、hash、数字、二进制(图片、音频、视频)等,最大不能超过512M。
2.1.2 Redis简单动态字符串(SDS)
Redis没有直接使用C语言传统的字符串表示(以空字符结尾的字符数组,以下简称C字符串),而是自己构建了一种名为简单动态字符串(simple dynamic string,SDS)的抽象类型,并将SDS用作Redis的默认字符串表示。
每个sds.h/sdshdr结构表示一个SDS值:
struct sdshdr {
// 记录 buf 数组中已使用字节的数量
// 等于 SDS 所保存字符串的长度
int len;
// 记录 buf 数组中未使用字节的数量
int free;
// 字节数组,用于保存字符串
char buf[];
};SDS遵循C字符串以空字符结尾的惯例,保存空字符的1字节空间不计算在SDS的len属性里面,并且为空字符分配额外的1字节空间,以及添加空字符到字符串末尾等操作都是由SDS函数自动完成的,所以这个空字符对于SDS的使用者来说是完全透明的。
2.1.3 内部编码
字符串对象的内部编码(encoding)有3种:int、raw和embstr。
可通过下面的命令查看当前String类型的内部编码:
redis> SET number 10086
OK
redis> OBJECT ENCODING number
"int"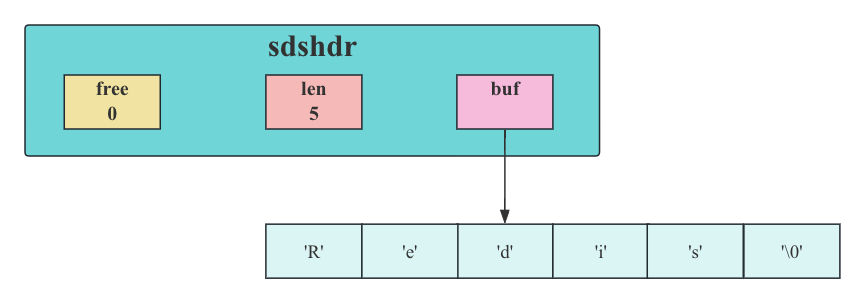
+
free属性的值为0,表示这个SDS没有分配任何未使用空间。+
len属性的值为5,表示这个SDS保存了一个五字节长的字符串。+
buf属性是一个char类型的数组,数组的前五个字节分别保存了’R’、’e’、’d’、’i’、’s’五个字符,而最后一个字节则保存了空字符’\0’。另一个实例,主要说明free属性的作用: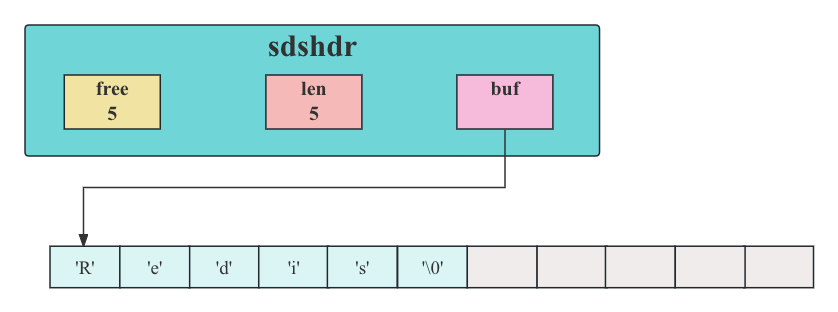
- 这个SDS和之前展示的SDS一样,都保存了字符串值
"Redis"。 - 这个SDS和之前展示的SDS的区别在于,这个SDS为
buf数组分配了五字节未使用空间,所以它的free属性的值为5(图中使用五个空格来表示五字节的未使用空间)。
如果一个字符串对象保存的是
整数值,并且这个整数值可以用long类型来表示,那么字符串对象会将整数值保存在字符串对象结构的ptr属性里面(将void*转换成long),并将字符串对象的编码设置为int。 编码类型为int
编码类型为int如果字符串对象保存的是一个
字符串,并且这个字符申的长度小于等于32字节(redis 2.+版本),那么字符串对象将使用一个简单动态字符串来保存这个字符串,并将对象的编码设置为embstr,embstr编码是专门用于保存短字符串的一种优化编码方式: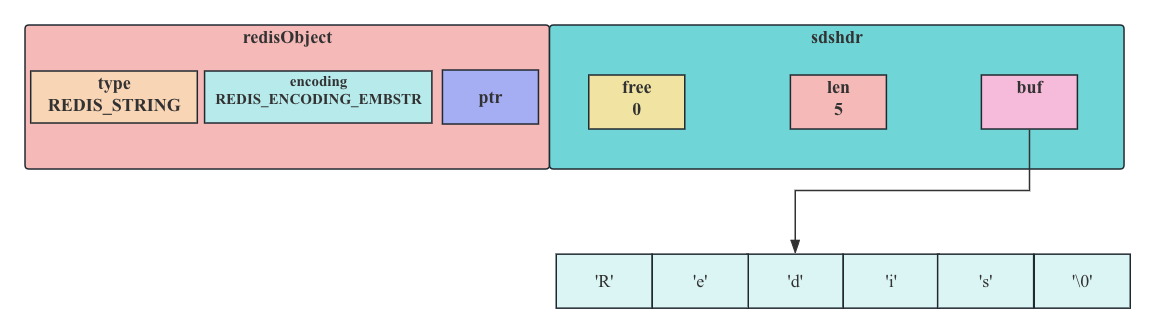 编码类型为embstr
编码类型为embstr如果字符串对象保存的是一个
字符串,并且这个字符串的长度大于32字节(redis 2.+版本),那么字符串对象将使用一个简单动态字符串来保存这个字符串,并将对象的编码设置为raw: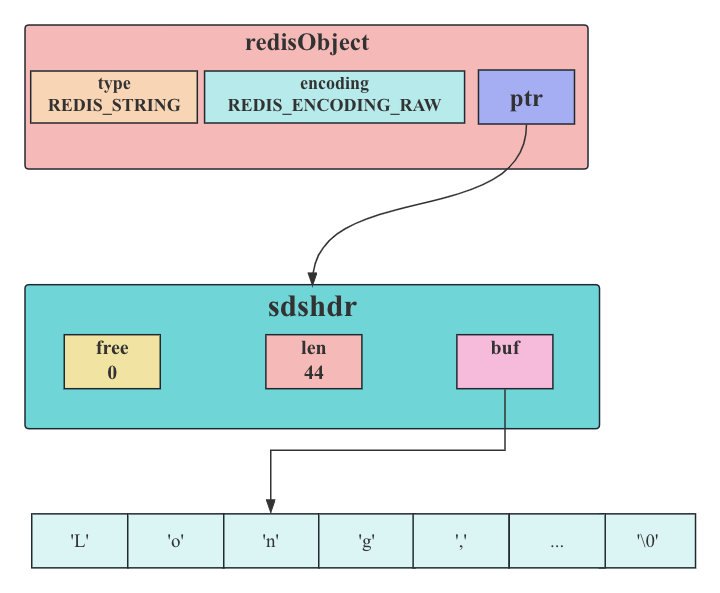 编码类型为raw
编码类型为raw
至于embstr和raw,读者可能有疑问,为啥RedisObject与sdshdr一个挨着,一个分开?
embstr编码是专门用于保存短字符串的一种优化编码方式,这种编码和raw编码一样,都使用redisObject结构和sdshdr结构来表示字符串对象,但raw编码会调用两次内存分配函数来分别创建redisObject结构和sdshdr结构,而embstr编码则通过调用一次内存分配函数来分配一块连续的空间,空间中依次包含redisObject和sdshdr两个结构.
embstr编码的字符串对象在执行命令时,产生的效果和raw编码的字符串对象执行命令时产生的效果是相同的,但使用embstr编码的字符串对象来保存短字符串值有以下好处:
- embstr编码将创建字符串对象所需的内存分配次数从raw编码的
两次降低为一次。 - 释放embstr编码的字符串对象只需要调用一次内存释放函数,而释放raw编码的字符串对象需要调用两次内存释放函数。
- 因为embstr编码的字符串对象的所有数据都保存在一块连续的内存里面,所以这种编码的字符串对象比起raw编码的字符串对象能够更好地利用缓存带来的优势。
注意,
embstr编码和raw编码的边界在redis不同版本中是不一样的:
- redis 2.+是32字节
- redis 3.0-4.0是39字节
- redis 5.0是44字节
但是embstr也有缺点的:
如果字符串的长度增加需要重新分配内存时,整个
redisObject和sdshdr都需要重新分配空间,所以embstr编码的字符串对象实际上是只读的,redis没有为embstr编码的字符串对象编写任何相应的修改程序。当我们对embstr编码的字符串对象执行任何修改命令(例如append)时,程序会先将对象的编码从embstr转换成raw,然后再执行修改命令。
2.1.4 常用命令
| 命令 | int编码的实现方法 | embstr编码的实现方法 | raw编码的实现方法 |
|---|---|---|---|
| SET | 使用int编码保存值。 | 使用embstr编码保存值。 | 使用raw编码保存值。 |
| GET | 拷贝对象所保存的整数值,将这个拷贝转换成字符串值,然后向客户端返回这个字符串值。 | 直接向客户端返回字符串值。 | 直接向客户端返回字符串值。 |
| APPEND | 将对象转换成raw编码,然后按raw编码的方式执行此操作。 | 将对象转换成raw编码,然后按raw编码的方式执行此操作。 | 调用sdscatlen函数,将给定字符串追加到现有字符串的末尾。 |
| INCRBYFLOAT | 取出整数值并将其转换成longdouble类型的浮点数,对这个浮点数进行加法计算,然后将得出的浮点数结果保存起来。 | 取出字符串值并尝试将其转换成longdouble类型的浮点数,对这个浮点数进行加法计算,然后将得出的浮点数结果保存起来。如果字符串值不能被转换成浮点数,那么向客户端返回一个错误。 | 取出字符串值并尝试将其转换成longdouble类型的浮点数,对这个浮点数进行加法计算,然后将得出的浮点数结果保存起来。如果字符串值不能被转换成浮点数,那么向客户端返回一个错误。 |
| INCRBY | 对整数值进行加法计算,得出的计算结果会作为整数被保存起来。 | embstr编码不能执行此命令,向客户端返回一个错误。 | raw编码不能执行此命令,向客户端返回一个错误。 |
| DECRBY | 对整数值进行减法计算,得出的计算结果会作为整数被保存起来。 | embstr编码不能执行此命令,向客户端返回一个错误。 | raw编码不能执行此命令,向客户端返回一个错误。 |
| STRLEN | 拷贝对象所保存的整数值,将这个拷贝转换成字符串值,计算并返回这个字符串值的长度。 | 调用sdslen函数,返回字符串的长度。 | 调用sdslen函数,返回字符串的长度。 |
| SETRANGE | 将对象转换成raw编码,然后按raw编码的方式执行此命令。 | 将对象转换成raw编码,然后按raw编码的方式执行此命令。 | 将字符串特定索引上的值设置为给定的字符。 |
| GETRANGE | 拷贝对象所保存的整数值,将这个拷贝转换成字符串值,然后取出并返回字符串指定索引上的字符。 | 直接取出并返回字符串指定索引上的字符。 | 直接取出并返回字符串指定索引上的字符。 |
2.1.5 应用场景
缓存,计数,共享session,限速
2.2 Hash
2.2.1 介绍
Hash是一个键值对(key - value)集合,其中 value 的形式如:value=[{field1,value1},...{fieldN,valueN}]。Hash 特别适合用于存储对象。
Hash 与 String 对象的区别如下图所示:
2.2.2 内部编码
Hash 类型的底层数据结构是由压缩列表(ziplist)或哈希表(hashtable)实现的:
- 如果哈希类型元素个数
小于 512 个(默认值,可由hash-max-ziplist-entries配置),且所有值小于 64 字节(默认值,可由hash-max-ziplist-value配置)的话,Redis 会使用压缩列表作为 Hash 类型的底层数据结构; - 如果哈希类型元素不满足上面条件,Redis 会使用
哈希表作为 Hash 类型的底层数据结构。在
Redis 7.0中,压缩列表数据结构已经废弃了,交由listpack数据结构来实现了。
2.2.3 ziplist
ziplist是为了提高存储效率而设计的一种特殊编码的双向链表。它可以存储字符串或者整数,存储整数时是采用整数的二进制而不是字符串形式存储。它能在O(1)的时间复杂度下完成list两端的push和pop操作。但是因为每次操作都需要重新分配ziplist的内存,所以实际复杂度和ziplist的内存使用量相关。
其结构1大致如下:
压缩列表各个组成部分的详细说明
| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4 字节 | 记录整个压缩列表占用的内存字节数:在对压缩列表进行内存重分配, 或者计算 zlend 的位置时使用。 |
| zltail | uint32_t | 4 字节 | 记录压缩列表表尾节点距离压缩列表的起始地址有多少字节: 通过这个偏移量,程序无须遍历整个压缩列表就可以确定表尾节点的地址。 |
| zllen | uint16_t | 2 字节 | 记录了压缩列表包含的节点数量: 当这个属性的值小于 UINT16_MAX (65535)时, 这个属性的值就是压缩列表包含节点的数量; 当这个值等于 UINT16_MAX 时, 节点的真实数量需要遍历整个压缩列表才能计算得出。 |
| entryX2 | 列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定。 |
| zlend | uint8_t | 1 字节 | 特殊值 0xFF (十进制 255 ),用于标记压缩列表的末端。 |
压缩列表节点(entry)包含三部分内容:
prevlen,记录了「前一个节点」的长度,目的是为了实现从后向前遍历;encoding,记录了当前节点实际数据的「类型和长度」,类型主要有两种:字符串和整数。data,记录了当前节点的实际数据,类型和长度都由 encoding 决定;
优点:节省内存
当我们往压缩列表中插入数据时,压缩列表就会根据数据类型是字符串还是整数,以及数据的大小,会使用不同空间大小的prevlen和encoding这两个元素里保存的信息,这种根据数据大小和类型进行不同的空间大小分配的设计思想,正是 Redis 为了节省内存而采用的。缺点:
- 查找复杂度高
- 连锁更新:压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配。而当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。3
2.2.4 hashtable
Redis 的哈希表结构如下:
typedef struct dictht {
//哈希表数组
dictEntry **table;
//哈希表大小
unsigned long size;
//哈希表大小掩码,用于计算索引值
unsigned long sizemask;
//该哈希表已有的节点数量
unsigned long used;
} dictht;可以看到,哈希表是一个数组(dictEntry **table),数组的每个元素是一个指向「哈希表节点(dictEntry)」的指针。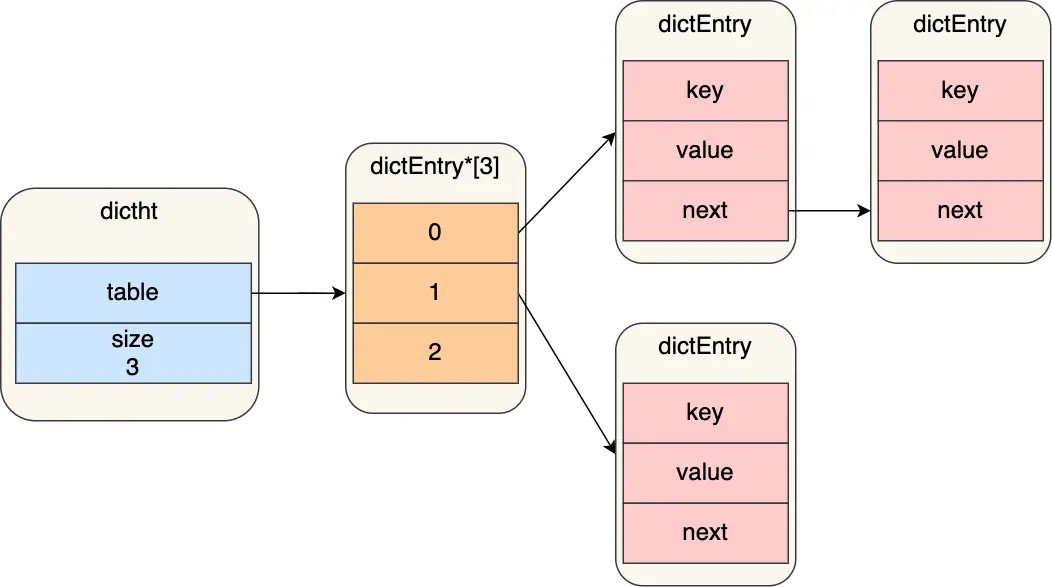
dictEntry 结构定义如下:
typedef struct dictEntry{
//键
void *key;
//值
union{
void *val;
uint64_tu64;
int64_ts64;
}v;
//指向下一个哈希表节点,形成链表
struct dictEntry *next;
}dictEntrydictEntry结构里不仅包含指向键和值的指针,还包含了指向下一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对链接起来,以此来解决哈希冲突的问题,这就是链式哈希。另外,dictEntry结构里键值对中的值是一个联合体 v定义的,因此,键值对中的值可以是一个指向实际值的指针,或者是一个无符号的 64 位整数或有符号的 64 位整数或double 类的值。这么做的好处是可以节省内存空间,因为当「值」是整数或浮点数时,就可以将值的数据内嵌在 dictEntry 结构里,无需再用一个指针指向实际的值,从而节省了内存空间。
2.2.5 常用命令
| 命令 | 简述 | 使用 |
|---|---|---|
| HSET | 添加键值对 | HSET hash-key sub-key1 value1 |
| HGET | 获取指定散列键的值 | HGET hash-key key1 |
| HGETALL | 获取散列中包含的所有键值对 | HGETALL hash-key |
| HDEL | 如果给定键存在于散列中,那么就移除这个键 | HDEL hash-key sub-key1 |
2.2.6 应用场景
缓存对象、购物车
2.3 list
2.3.1 介绍
List列表是简单的字符串列表,按照插入顺序排序,列表元素可重复,最多$2^{32}$-1个元素。可以从头部或尾部向 List 列表添加元素。
2.3.2 内部编码
List 类型的底层数据结构是由双向链表(linkedlist)或压缩列表(ziplist)实现的:
- 如果列表的元素个数
小于 512 个(默认值,可由list-max-ziplist-entries配置),且列表每个元素的值都小于 64 字节(默认值,可由list-max-ziplist-value配置),Redis 会使用压缩列表作为 List 类型的底层数据结构; - 如果列表的元素不满足上面的条件,Redis 会使用
双向链表作为 List 类型的底层数据结构;
但是在Redis 3.2版本之后,List 数据类型底层数据结构就只由quicklist4实现了,替代了双向链表和压缩列表。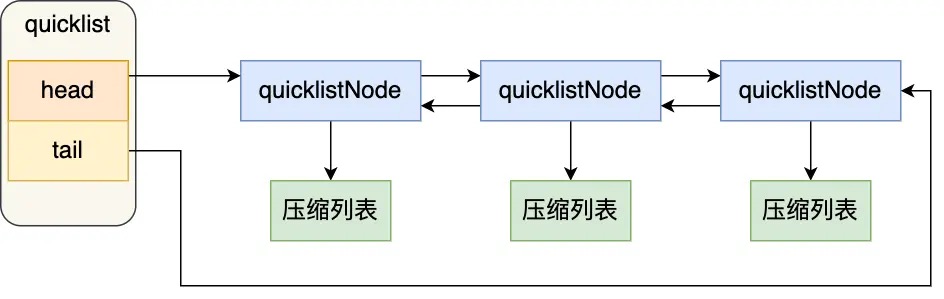 QuickList
QuickList
2.3.3 常用命令
| 命令 | 简述 | 使用 |
|---|---|---|
| RPUSH | 将给定值推入到列表右端 | RPUSH key value |
| LPUSH | 将给定值推入到列表左端 | LPUSH key value |
| RPOP | 从列表的右端弹出一个值,并返回被弹出的值 | RPOP key |
| LPOP | 从列表的左端弹出一个值,并返回被弹出的值 | LPOP key |
| LRANGE | 获取列表在给定范围上的所有值 | LRANGE key 0 -1 |
| LINDEX | 通过索引获取列表中的元素。也可以使用负数下标,以-1表示列表的最后一个元素,-2表示列表的倒数第二个元素,以此类推。 | LINDEX key index |
使用列表的技巧
- lpush+lpop=Stack(栈)
- lpush+rpop=Queue(队列)
- lpush+ltrim=Capped Collection(有限集合)
- lpush+brpop=Message Queue(消息队列)
2.3.4 应用场景
消息队列、微博TimeLine。
2.4 set
2.4.1 介绍
与list最大不同,set集合内元素唯一且无序。一个集合最多可以存储 $2^{32}$-1 个元素。概念和数学中个的集合基本类似,可以交集,并集,差集等等,所以 Set 类型除了支持集合内的增删改查,同时还支持多个集合取交集、并集、差集。
潜在的风险。Set 的差集、并集和交集的计算复杂度较高,在
数据量较大的情况下,如果直接执行这些计算,会导致 Redis 实例阻塞。
2.4.2 内部编码
Set 类型的底层数据结构是由哈希表或整数集合5实现的:
- 如果集合中的元素都是
整数且元素个数小于 512(默认值,set-maxintset-entries配置)个,Redis 会使用整数集合作为 Set 类型的底层数据结构; - 如果集合中的元素不满足上面条件,则 Redis 使用
哈希表作为 Set 类型的底层数据结构。
2.4.3 常用命令
| 命令 | 简述 | 使用 |
|---|---|---|
| SADD | 向集合添加一个或多个成员 | SADD key value |
| SCARD | 获取集合的成员数 | SCARD key |
| SMEMBERS | 返回集合中的所有成员 | SMEMBERS key member |
| SISMEMBER | 判断 member 元素是否是集合 key 的成员 | SISMEMBER key member |
2.4.4 应用场景
点赞、标签、共同关注、抽奖活动。
2.5 zset
2.5.1 介绍
Redis有序集合(Zset)和集合(set)一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
2.5.2 内部编码
Zset类型的底层数据结构是由压缩列表或跳表实现的:
- 如果有序集合的元素个数
小于 128 个,并且每个元素的值均小于 64 字节时,Redis 会使用压缩列表作为 Zset 类型的底层数据结构; - 如果有序集合的元素不满足上面的条件,Redis 会使用
跳表6作为 Zset 类型的底层数据结构;在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由
listpack数据结构来实现了.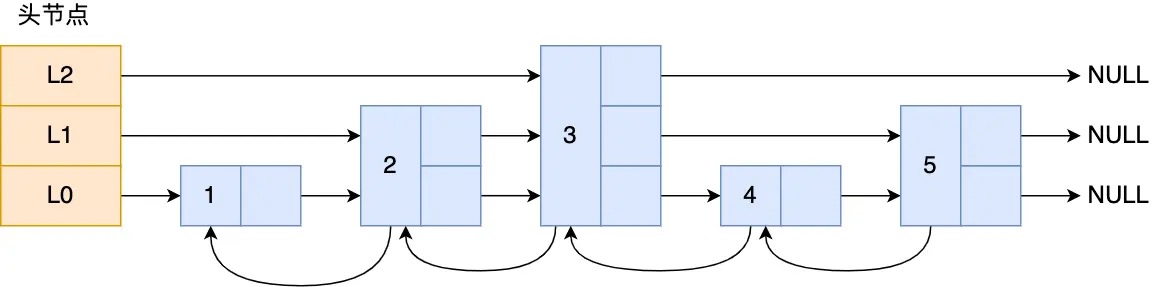 跳表结构示意图
跳表结构示意图
2.5.3 常用命令
| 命令 | 简述 | 使用 |
|---|---|---|
| ZADD | 将一个带有给定分值的成员添加到有序集合里面 | ZADD zset-key 178 member1 |
| ZRANGE | 根据元素在有序集合中所处的位置,从有序集合中获取多个元素 | ZRANGE zset-key 0-1 withccores |
| ZREM | 如果给定元素成员存在于有序集合中,那么就移除这个元素 | ZREM zset-key member1 |
2.5.4 应用场景
- 排行榜:有序集合经典使用场景。例如小说视频等网站需要对用户上传的小说视频做排行榜,榜单可以按照用户关注数,更新时间,字数等打分,做排行。
2.6 位图
2.6.1 介绍
Bitmap,即位图数据结构,都是操作二进制位来进行记录,只有0和1两个状态。
BitMap通过最小的单位bit来进行0|1的设置,表示某个元素的值或者状态,时间复杂度为O(1)。
2.6.2 内部实现
Bitmap 本身是用 String 类型作为底层数据结构实现的一种统计二值状态的数据类型。
String 类型是会保存为二进制的字节数组,所以,Redis 就把字节数组的每个 bit 位利用起来,用来表示一个元素的二值状态,你可以把 Bitmap 看作是一个 bit 数组。
2.6.3 常用命令
| 命令 | 简述 | 使用 |
|---|---|---|
| SETBIT | 设定key对应value,其中value为0或1,不能为其他值 | SETBIT key offset value |
| GETBIT | 获取key对应的value | GETBIT key offset |
| BITCOUNT | 获取指定范围内值为 1 的个数,start 和 end 以字节为单位 | BITCOUNT key start end |
| BITPOS | 返回指定key中第一次出现指定value(0/1)的位置 | BITPOS [key] [value] |
2.6.4 应用场景
签到、打卡、判断用户登陆态、连续签到用户总数
2.7 GEO
2.7.1 介绍
Redis 的 GEO 在 Redis 3.2 版本就推出了! 这个功能可以推算地理位置的信息: 两地之间的距离, 方圆几里的人.
2.7.2 内部实现
GEO 本身并没有设计新的底层数据结构,而是直接使用了Sorted Set集合类型。
GEO 类型使用 GeoHash 编码方法实现了经纬度到Sorted Set中元素权重分数的转换,这其中的两个关键机制就是「对二维地图做区间划分」和「对区间进行编码」。一组经纬度落在某个区间后,就用区间的编码值来表示,并把编码值作为Sorted Set元素的权重分数。
这样一来,我们就可以把经纬度保存到Sorted Set中,利用Sorted Set提供的“按权重进行有序范围查找”的特性,实现 LBS 服务中频繁使用的“搜索附近”的需求。
2.7.3 常用命令
2.7.4 应用场景
滴滴叫车.
2.8 HyperLogLog
2.8.1 介绍
Redis HyperLogLog是 Redis 2.8.9 版本新增的数据类型,是一种用于「统计基数」的数据集合类型,基数统计就是指统计一个集合中不重复的元素个数。但要注意,HyperLogLog 是统计规则是基于概率完成的,不是非常准确,标准误算率是 0.81%。
基数统计,举个例子,
A = {1, 2, 3, 4, 5},B = {3, 5, 6, 7, 9};那么基数(不重复的元素)=1, 2, 4, 6, 7, 9; (允许容错,即可以接受一定误差)。
所以,简单来说 HyperLogLog 提供不精确的去重计数。
- 优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的内存空间总是固定的、并且是很小的。
一个大型的网站,每天 IP 比如有
100万,粗算一个 IP 消耗15 字节,那么100万个 IP 就是15M。而 HyperLogLog 在 Redis 中每个键占用的内容都是12K,理论存储近似接近 $2^{64}$ 个值,不管存储的内容是什么,它一个基于基数估算的算法,只能比较准确的估算出基数,可以使用少量固定的内存去存储并识别集合中的唯一元素。而且这个估算的基数并不一定准确,是一个带有0.81%标准错误的近似值(对于可以接受一定容错的业务场景,比如IP数统计,UV等,是可以忽略不计的)。
2.8.2 内部实现
2.8.3 常用命令
| 命令 | 简述 | 使用 |
|---|---|---|
| PFADD | 添加指定元素到 HyperLogLog 中 | PFADD key element [element …] |
| PFCOUNT | 返回给定 HyperLogLog 的基数估算值。 | PFCOUNT key [key …] |
| PFMERGE | 将多个 HyperLogLog 合并为一个 HyperLogLog | PFMERGE destkey sourcekey [sourcekey …] |
2.8.4 应用场景
百万级网页 UV 计数。
2.9 Stream
2.9.1 介绍
Redis Stream是Redis 5.0版本新增加的数据类型,Redis 专门为消息队列设计的数据类型。
基于Redis的消息队列实现有很多种,例如:
PUB/SUB,发布/订阅模式,但是发布订阅模式是无法持久化的,如果出现网络断开、Redis 宕机等,消息就会被丢弃;并且对于离线重连的客户端不能读取历史消息的缺陷;- 基于List
LPUSH + BRPOP或者基于Sorted-Set的实现,支持了持久化,但是不支持多播,分组消费等。
基于以上问题,Redis 5.0便推出了Stream类型也是此版本最重要的功能,用于完美地实现消息队列,它支持消息的持久化、支持自动生成全局唯一 ID、支持ack 确认消息的模式、支持消费组模式等,让消息队列更加的稳定和可靠。
2.9.2 常见命令
| 命令 | 简述 | 使用 |
|---|---|---|
| XADD | 插入消息(尾插),保证有序,可以自动生成全局唯一 ID; | xadd codehole * key value key value |
| XLEN | 查询消息长度; | xlen codehole |
| XREAD | 用于读取消息,可以按 ID 读取数据; | XREAD STREAMS mymq 1654254953807-0 |
| XDEL | 根据消息 ID 删除消息; | xdel codehole 1527849609889-0 |
| DEL | 删除整个 Stream; | del codehole # 删除整个Stream |
| XGROUP | 创建消费者组 | 创建一个名为 group1 的消费组,0-0表示从第一条消息开始读取。XGROUP CREATE mymq group1 0-0 |
| XRANGE | 读取区间消息 | |
| XREADGROUP | 按消费组形式读取消息; | |
| XPENDING | 命令可以用来查询每个消费组内所有消费者「已读取、但尚未确认」的消息; | XPENDING mymq group2 |
| XACK | 命令用于向消息队列确认消息处理已完成; | XACK mymq group2 1654256265584-0 |
注:
xadd中,*号表示服务器自动生成ID,后面顺序跟着一堆key/value;XREAD从这个消息 ID 的下一条消息开始进行读取(注意是输入消息 ID 的下一条信息开始读取,不是查询输入ID的消息);
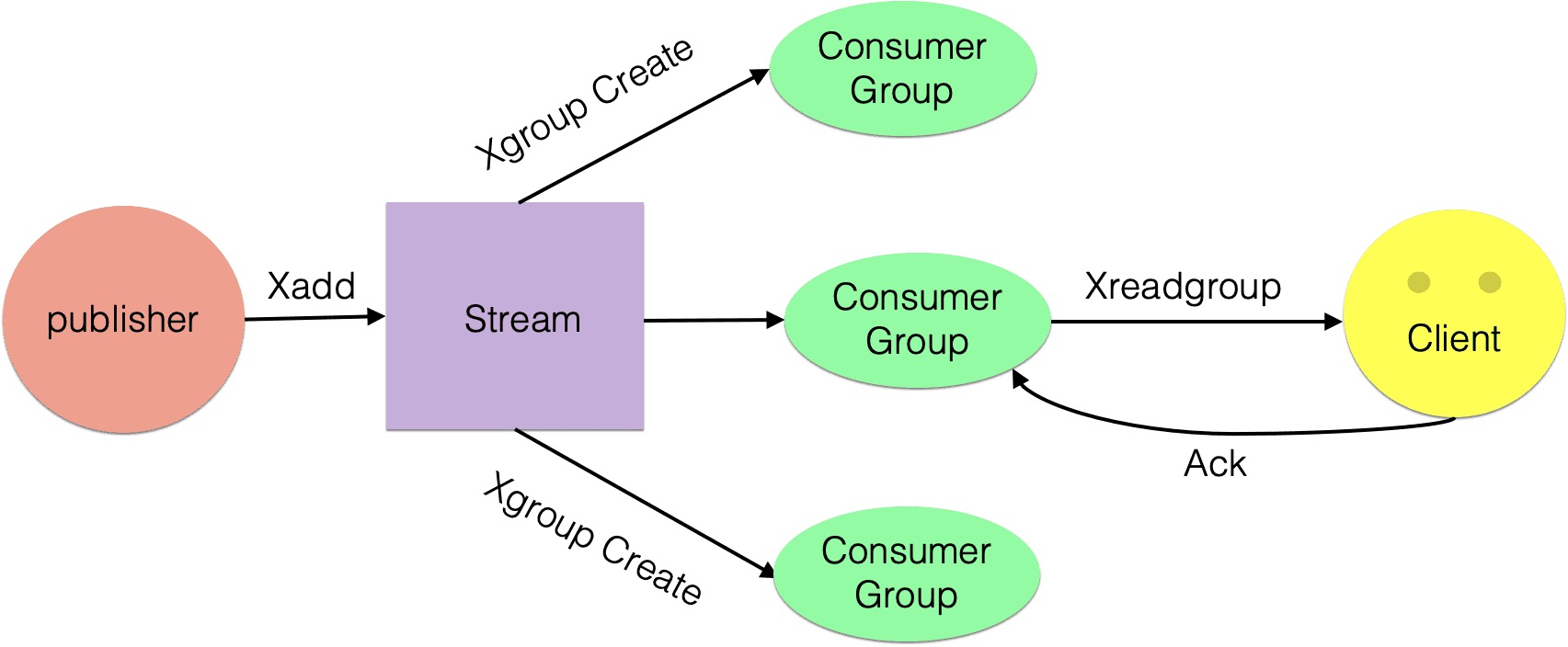
2.9.3 应用场景
消息队列



