1 索引的本质
帮助MySQL高效获取数据的数据结构。
2 索引分类
- 数据结构维度:B+树索引,Hash索引,全文索引(Full Text),R树索引。
- 物理存储维度:聚集索引,非聚集索引。
- 逻辑维度:空间索引(Spatial Index),唯一索引(Unique),联合索引,普通索引(Normal),主键索引(Primary Key)。
2.1 B+树索引
2.1.1 二叉树
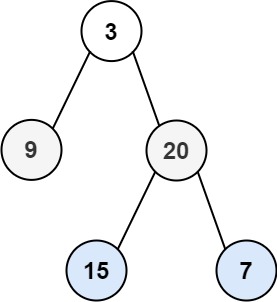
每个节点至多只有二棵子树,左子树和右子树,次序不能颠倒。
逻辑上二叉树有五种基本形态:空二叉树、只有一个根结点的二叉树、只有左子树、只有右子树、完全二叉树(特例为满二叉树)。
遍历是对树的一种最基本的运算,所谓遍历二叉树,就是按一定的规则和顺序走遍二叉树的所有结点,使每一个结点都被访问一次,而且只被访问一次,有前序、中序、后序遍历。
2.1.2 二叉查找(搜索)树
二叉查找树首先肯定是颗二叉树,除此之外还规定,在二叉查找树中,左子树的节点值总是小于根的节点值,右子树的节点值总是大于根的节点值,也就是:
左子树节点值 < 根的节点值 < 右子树节点值。
它的查找时间复杂度和二分查找一样,O(logN)。
但是二叉查找树,如果设计不良,完全可以变成一颗极不平衡的二叉查找树: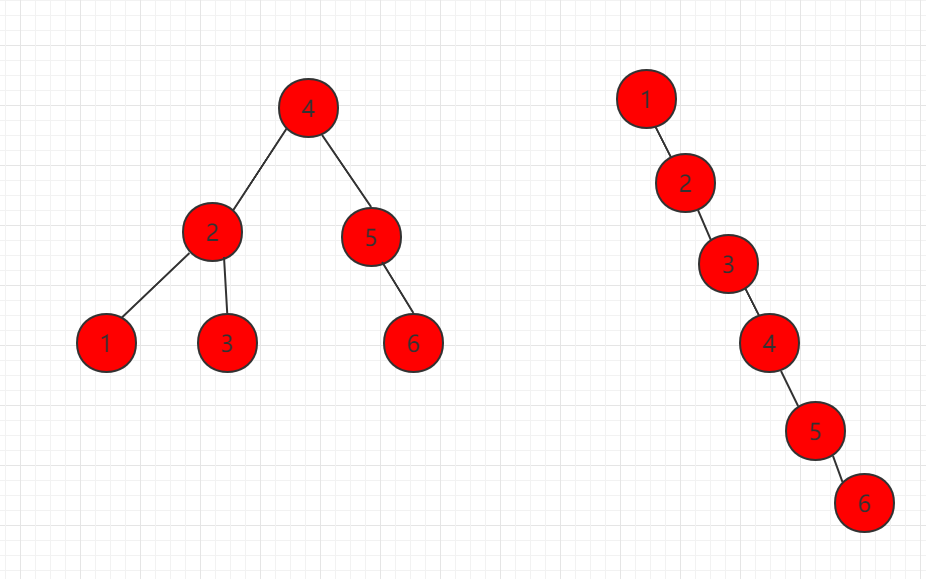
查找效率和顺序查找基本没差别了。因此若想最大性能地构造一棵二叉查找树,需要这棵二叉查找树是平衡的,从而引出了新的定义——平衡二叉树,或称为AVL树。
2.1.3 平衡二叉树(AVL树)
首先符合二叉查找树的定义,其次必须满足任何节点的两个子树的高度最大差为 1。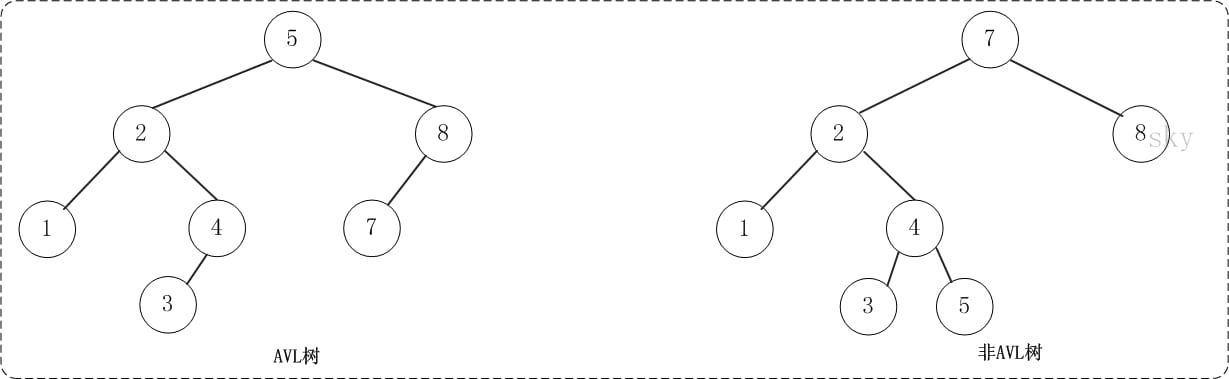
平衡二叉树对一个数据库来说,有什么问题?
因为二叉树每个节点
最多只有两个直属子节点,所以当节点数比较多时,二叉树的高度增长很快,比如 1000 个节点时,树的高度差不多有 9 到 10 层。我们知道数据库是持久化的,数据是要从磁盘上读取的,一般的机械磁盘每秒至少可以做 100 次 IO,一次 IO 的时间基本上在 0.01 秒,1000 个节点在查找时就需要 0.1 秒,如果是 10000 个节点,100000 个节点呢?
所以对数据库来说,为了减少树的高度,提出了B+树的数据结构。2.1.4 B+树
一棵
m 阶的 B+树定义如下:
- 每个节点
最多可以有m个元素;- 除了根节点外,每个节点最少有
(m/2)个元素;- 如果根节点不是叶节点,那么它
最少有2个孩子节点;- 所有的叶子节点都在
同一层;- 一个有
k个孩子节点的非叶子节点有(k-1)个元素,按升序排列;- 某个元素的左子树中的元素都比它小,右子树的元素都大于或等于它;
非叶子节点只存放关键字和指向下一个孩子节点的索引,记录只存放在叶子节点中;- 相邻的叶子节点之间用
指针相连。
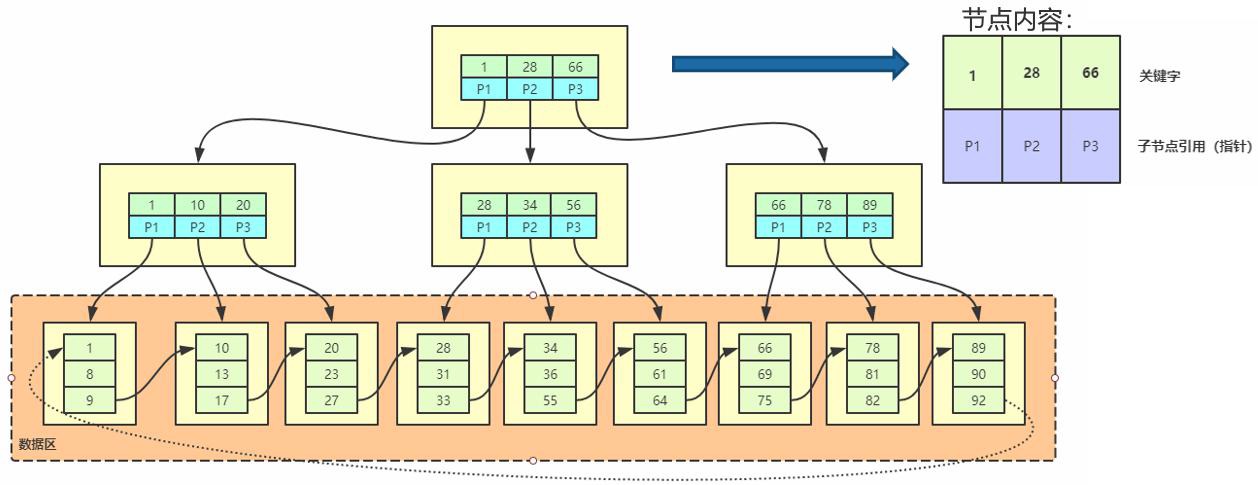
B+树索引是大多数 MySQL 存储引擎的默认索引类型。因为不再需要进行全表扫描,只需要对树进行搜索即可,因此查找速度快很多。
除了用于查找,还可以用于排序和分组。可以指定多个列作为索引列,多个索引列共同组成键。
适用于全键值、键值范围和键前缀查找,其中键前缀查找只适用于最左前缀查找。如果不是按照索引列的顺序进行查找,则无法使用索引。
InnoDB 的 B+树索引分为主键索引(聚集索引)和辅助索引(非聚集索引、二级索引)。
2.2 Hash索引
适合等值查询,检索效率高,一次到位。
- 局限
- hash 表只能匹配是否相等,不能实现范围查找;
- 当需要按照索引进行order by 时,hash 值没办法支持排序;
- 组合索引(composite index)可以支持部分索引查询,如(a,b,c)的组合索引,查询中只用到了a和b 也可以查询的,如果使用hash 表,组合索引会将几个字段合并hash,
没办法支持部分索引; - 当数据量很大时,
hash 冲突(hash collision)的概率也会非常大.
2.2.1 自适应 Hash 索引
InnoDB 存储引擎内部自己去监控索引表,如果监控到某个索引经常用,那么就认为是热数据,然后内部自己创建一个hash 索引;
我们并不能对其进行干预。通过命令 show engine innodb status\G 可以看到当前自适应哈希索引的使用状况.
2.3 全文索引(Full Text)
MyISAM和InnoDB中都支持使用全文索引,一般在文本类型char,text,varchar类型上创建。
全文索引一般使用倒排索引实现,它记录着关键词到其所在文档的映射。
InnoDB 存储引擎在
MySQL v5.6.4版本中也开始支持全文索引。
2.4 R树索引
用来对GIS数据类型创建SPATIAL索引。
3 索引在查询中的使用
一个索引就是一个B+树,索引让我们的查询可以快速定位和扫描到我们需要的数据记录上,加快查询的速度。
一个select 查询语句在执行过程中一般最多能使用一个二级索引,即使在where 条件中用了多个二级索引。
4 索引的代价
4.1 空间上的代价
每建立一个索引都要为它建立一棵B+树,每一棵B+树的每一个节点都是一个数据页,一个页默认会占用16KB 的存储空间,一棵很大的B+树由许多数据页组成会占据很多的存储空间。
4.2 时间上的代价
每次对表中的数据进行增、删、改操作时,都需要去修改各个B+树索引。
5 高性能的索引创建策略
5.1 索引列的类型尽量小
- 数据类型越小,在查询时进行的
比较操作越快(CPU 层次) - 数据类型越小,索引占用的
存储空间就越少,在一个数据页内就可以放下更多的记录,从而减少磁盘I/O带来的性能损耗,也就意味着可以把更多的数据页缓存在内存中,从而加快读写效率。
5.2 索引选择性和前缀索引
- 创建索引应该选择选择性/离散性高的列.
- 前缀索引
5.3 只为用于搜索、排序或分组的列创建索引
- 只为出现在
WHERE 子句中的列、连接子句中的连接列创建索引; - 覆盖索引
- 为出现在
ORDER BY或GROUP BY子句中的列创建索引:ORDER BY、group by的子句后边的列的顺序也必须按照索引列的顺序给出。
5.4 多列索引
- 将
选择性最高的列放到索引最前列; - 最左匹配;
- 索引下推 Index Condition Pushdown(ICP)。
索引下推:只需要通过索引中的列就能够评估行是否符合WHERE中的一部分条件,MySQL将这部分WHERE条件
下推到存储引擎中,然后存储引擎评估使用索引条目来评估下推的索引条件,并只从表中读取符合条件的行。
5.5 设计三星索引
- 一星(范围星)27% :索引将相关的记录放到一起;
- 二星(排序星)23%:索引中的数据顺序和查找中的排列顺序一致;
- 三星(宽索引星)50%:索引中的列包含了查询中需要的全部列。
5.6 主键是很少改变的列
行是按照聚集索引物理排序的,如果主键频繁改变(update),物理顺序会改变,MySQL 要不断调整B+树,并且中间可能会产生页面的分裂和合并等等,会导致性能会急剧降低。
5.7 冗余和重复索引
MySQL 允许在相同列上创建多个索引,无论是有意的还是无意的。MySQL需要单独维护重复的索引,并且优化器在优化查询的时候也需要逐个地进行考虑,这会影响性能。
重复索引是指在相同的列上按照相同的顺序创建的相同类型的索引。应该避免这样创建重复索引,发现以后也应该立即移除。5.8 删除未使用的索引
除了冗余索引和重复索引,可能还会有一些服务器永远不用的索引。这样的索引完全很累赘,建议考虑删除。



